你可能感兴趣的文章
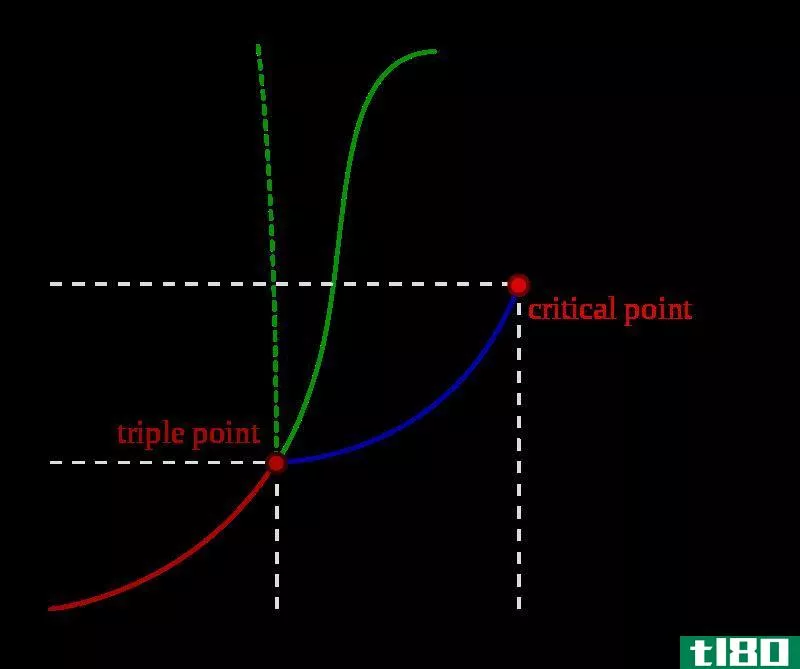
是的(true)和伪临界性质(pseudo critical properties)的区别
...界性质是系统的实际临界性质,它是由热力学确定的,而伪临界性质是系统中每一个纯组分对某一特定反应的表观贡献。 临界特性是指系统在临界点的温度和压力。热力学系统的临界点是该系统相平衡曲线的终点。它是液体与...
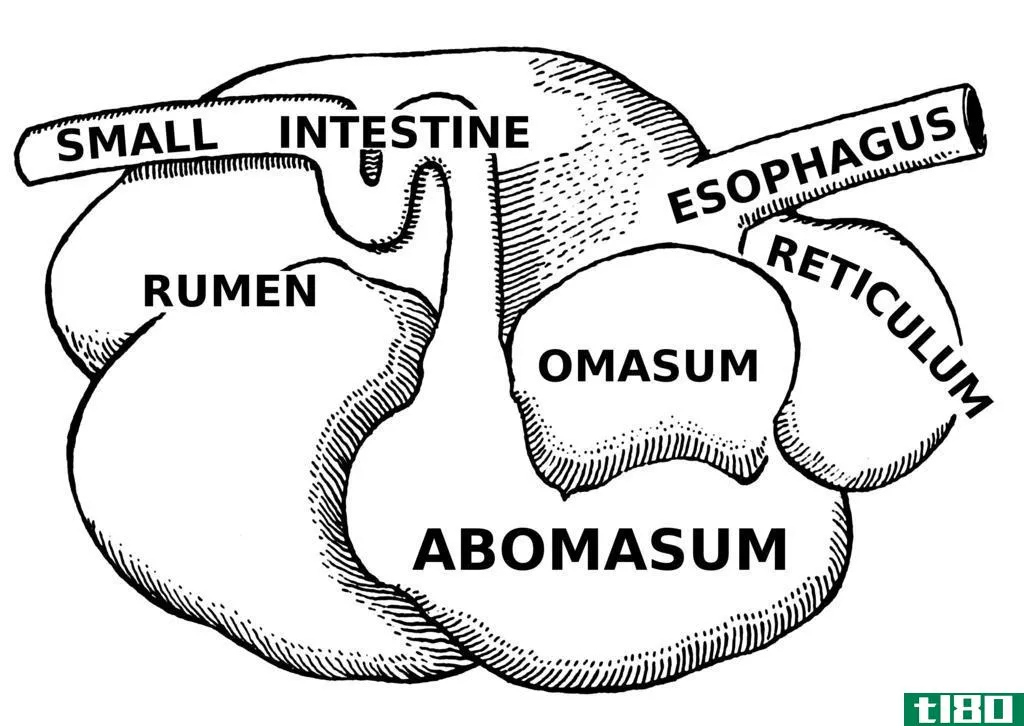
伪反刍动物(pseudo ruminant)和反刍动物系统(ruminant systems)的区别
伪反刍动物和反刍动物的主要区别在于,伪反刍动物消化系统在胃只有三个隔室,没有反刍动物,而反刍动物消化系统在包括反刍动物在内的大胃中有四个隔室。 消化系统有四种基本类型。它们是单胃消化系统、多胃消化系...
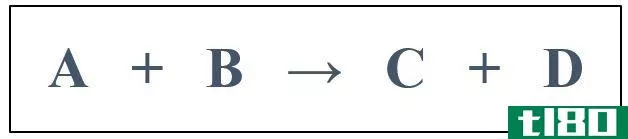
一级(first order)和拟一级反应(pseudo first order reaction)的区别
...关键区别在于,一级反应的速率仅与一个反应物浓度线性相关,而伪一级反应是二级反应,表现为一级反应。 下面是一级反应和伪一级反应之间差异的汇总表。 总结 - 一级(first order) vs. 拟一级反应(pseudo first order reaction) 一级反...

如何使用css选择器定位网页的一部分
... 相关:简单的CSS代码示例,你可以在10分钟内学会 ...

什么是linux上的tty?(以及如何使用tty命令)
...备文件连接到多路复用器。tty显示它是/dev/pts/2。 who tty 相关:如何在Linux中确定当前用户帐户 访问tty 您可以通过按住Ctrl+Alt键并按其中一个功能键来访问全屏TTY会话。 Ctrl+Alt+F3会弹出tty3的登录提示。 如果您登录并发出tty命令...

计算机如何产生随机数
...是类似的——它们试图得到一个不可预测的随机结果。 相关:什么是加密,它是如何工作的? 随机数生成器有许多不同的用途。除了为赌博目的生成随机数或在电脑游戏中产生不可预测的结果等明显的应用之外,随机性对于密...

去看看facebook的伪最高法院是怎么走到一起的
Facebook能有一个有意义的最高**吗? 《纽约客》上一篇由法学教授凯特科罗尼克撰写的新专题文章的标题暗示答案是肯定的。故事更复杂。 这一功能被称为“Facebook最高**的内部决策”,这是对Facebook监督委员会前所未...

从手机上获得酷炫的摄像效果,无需应用程序或手动控制即可点对点拍摄
...定曝光和焦距设置,这意味着你可以将相机指向第二个“伪对象”,锁定设置,然后指向你的常规对象。在适当的条件下,可以使用伪主题锁定所需的设置。使用“手动”曝光来修复冲洗过的照片这是我拍的一张曝光不足的照片...

假设(hypothesis)和目标(aim)的区别
...假设,是超越假设检验的目标。 它涉及到主题以及与之相关的所有数据和事实,这些数据和事实对于假设的评估和验证至关重要。每一个假设都应该有一个明确而具体的目标,以便能够更好地证明它的优点。 总结1。假设是对某...

什么是伪码(what is the pseudocode)和算法?(algorithm?)的区别
简单来说,伪代码是一种描述算法逻辑的叙述。 伪代码不是可执行代码,因此不必使用精确的语法;但是,遵循业界广泛使用的标准是很有帮助的,解决方案团队可以很容易地理解该标准。 统一建模语言(UML)和其他业务...
0 篇文章





