聚类(clustering)和分类(classification)的区别
聚类和分类技术被用于机器学习、信息检索、图像调查和相关任务中。
这两种策略是数据挖掘过程的两个主要部分。在数据分析领域,这些是管理算法所必需的。具体来说,这两个过程都将数据划分为多个集合。这项任务在当今的信息时代非常重要,因为数据的大量增加加上开发需要适当地加以促进。
值得注意的是,聚类和分类有助于通过数据科学解决犯罪、贫困和疾病等全球性问题。
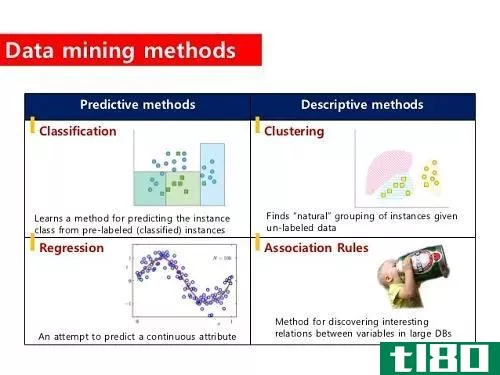
什么是聚类(clustering)?
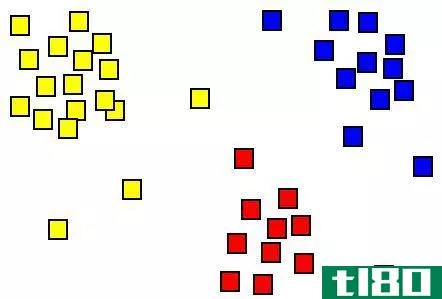
基本上,聚类涉及到根据相似性对数据进行分组。它主要涉及距离度量和聚类算法,这些算法计算数据之间的差异并对它们进行系统划分。
例如,学习风格相似的学生被分组在一起,与学习方法不同的学生分开授课。在数据挖掘中,聚类最常被称为“无监督学习技术”,因为聚类是基于一个自然的或固有的特征。
它应用于信息技术、生物学、犯罪学和医学等多个科学领域。
聚类特征:
- 没有确切的定义
聚类没有精确的定义,这就是为什么有各种聚类算法或聚类模型。粗略地说,这两种聚类是硬聚类和软聚类。硬聚类涉及到将一个对象标记为是否仅仅属于一个聚类。相比之下,软聚类或模糊聚类指定了某个事物如何属于某个组的程度。
- 难以评估
由于聚类分析固有的不精确性,其结果的验证或评价往往难以确定。
- 无监督的
由于它是一种无监督的学习策略,因此本文的分析仅基于当前的特点;因此,不需要严格的监管。

什么是分类(classification)?
分类需要为现有的情况或类别分配标签;因此,术语“分类”。例如,表现出某些学习特征的学生被归类为视觉学习者。
分类也被称为“监督学习技术”,机器从已经标记或分类的数据中学习。它非常适用于模式识别、统计和生物特征识别。
分类特点
- 使用“分类器”
为了分析数据,分类器是一种定义的算法,它具体地将信息映射到特定的类。例如,分类算法将训练一个模型来识别某个细胞是恶性的还是良性的。
- 通过通用指标进行评估
分类分析的质量通常是通过精度和召回来评估的,这是一种流行的度量方法。对分类器在识别输出时的精度和灵敏度进行了评估。
- 被监督的
分类是一种有监督的学习技术,因为它根据可比较的特征分配先前确定的身份。它从一个带标签的训练集导出一个函数。
聚类与分类的区别
- 监督
主要区别在于聚类是无监督的,被认为是“自学习”,而分类是有监督的,因为它依赖于预定义的标签。
- 训练集的使用
聚类并不尖锐地使用训练集,训练集是用来生成分组的实例组,而分类迫切需要训练集来识别相似的特征。
- 标记
聚类处理未标记的数据,因为它不需要训练。另一方面,分类处理过程中的未标记和标记数据。
- 目标
聚类的目的是缩小对象之间的关系,从隐藏的模式中学习新的信息,而分类的目的是确定某个对象属于哪个显式组。
- 细节
虽然分类并没有指定需要学习什么,但是聚类指定了所需的改进,因为它通过考虑数据之间的相似性来指出差异。
- 阶段
一般来说,聚类只包括一个阶段(分组),而分类分为两个阶段:训练阶段(模型从训练数据集中学习)和测试阶段(目标类被预测)。
- 边界条件
与聚类相比,边界条件的确定在分类过程中非常重要。例如,在建立分类时,需要知道“低”与“中等”和“高”的百分比范围。
- 预测
与聚类相比,分类更多地涉及到预测,因为它特别旨在识别目标类。例如,这可以应用于“面部关键点检测”,因为它可以用于预测某个证人是否撒谎。
- 复杂性
由于分类包含更多的阶段,涉及预测,涉及程度或层次,因此与聚类相比,分类的性质更为复杂,聚类主要涉及相似属性的分组。
- 或然算法数
聚类算法主要是线性和非线性的,而分类则由线性分类器、神经网络、核估计、决策树和支持向量机等算法工具组成。
聚类(clustering) vs. 分类:比较聚类和分类差异的表格(classification: table comparing the difference between clustering and classification)
| 聚类 | 分类 |
| 无监督数据 | 监督数据 |
| 不高度重视训练集 | 是否高度重视训练集 |
| 仅适用于未标记的数据 | 涉及未标记和标记的数据 |
| 旨在识别数据之间的相似性 | 旨在验证数据所属的位置 |
| 指定所需的更改 | 未指定所需的改进 |
| 有单相 | 有两个阶段 |
| 确定边界条件并不重要 | 确定边界条件是执行阶段的关键 |
| 一般不涉及预测 | 处理预测 |
| 主要采用两种算法 | 有许多可能的算法可供使用 |
| 过程不那么复杂 | 过程更复杂 |
总结 - 论聚类(on clustering) vs. 分类(classification)
- 聚类分析和分类分析在数据挖掘过程中得到了广泛的应用。
- 这些技术应用于解决全球问题所必需的各种科学领域。
- 聚类主要处理无监督数据;因此,未标记分类与监督数据一起工作;因此,标记。这是聚类不需要训练集而分类需要训练集的主要原因之一。
- 与聚类相比,与分类相关的算法更多。
- 聚类旨在验证数据之间的相似性或不相似性,而分类则侧重于确定数据的“类”或组。这使得聚类过程更侧重于边界条件,分类分析更复杂,因为它涉及更多的阶段。
- 发表于 2021-06-25 04:13
- 阅读 ( 715 )
- 分类:互联网
你可能感兴趣的文章
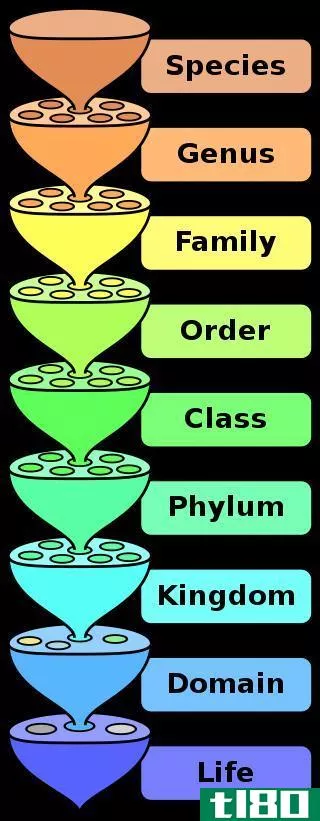
分类(classification)和二项式命名法(binomial nomenclature)的区别
...较——表格形式的分类与二项命名法 6. 摘要 什么是分类(classification)? 分类是根据相似性和不同性对生物体进行分组。它把生物组织成群,因此很容易对它们进行研究。分类是分类学中最重要的组成部分之一。有不同级别的分...

酚类(phenetics)和分支学(cladistics)的区别
...学有助于对各种系统进行分类,同时有助于对生物体进行聚类和分组。在这一点上,酚类和支系学在建立生物体之间的关系方面起着重要作用。 目录 1. 概述和主要区别 2. 什么是酚类 3. 什么是分支学 4. 酚类与分支学的相似性 5. ...
被监督的(supervised)和无监督机器学习(unsupervised machine learning)的区别
...机器学习相关的算法有很多种。其中一些是回归、分类和聚类。开发基于机器学习的应用程序最常用的编程语言是R和Python。也可以使用其他语言,如java、C++和MATLAB。 目录 1. 概述和主要区别 2. 什么是监督学习 3. 什么是无监督学...
丛生的(clustered)和非聚集索引(nonclustered index)的区别
...–以表格形式显示**索引与非**索引 6. 摘要 什么是**索引(clustered index)? 在**索引中,索引组织实际数据。它类似于电话簿。电话号码是按字母顺序排列的。在搜索特定姓名时,可以找到相应的电话号码。因此,聚类索引以有组...

分类(classification)和回归(regression)的区别
... 4. 并列比较-分类与表格形式的回归 5. 摘要 什么是分类(classification)? 分类是一种用于获得示意图的技术,该示意图显示以前体变量开始的数据组织。因变量是对数据进行分类的变量。 图01:数据挖掘 分类树从自变量开始,根...

分类(classification)和预测(prediction)的区别
分类(classification)和预测(prediction)的区别 分类和预测是与数据挖掘相关的两个术语。数据对于几乎所有的组织来说都是重要的,以增加利润和了解市场。纯数据没有多大价值。因此,为了得到有用的信息,应该对数据进行处理...
聚类(clustering)和分类(classification)的区别
... 4. 并列比较-聚类与表格形式的分类 5.摘要 什么是聚类(clustering)? 聚类是一种对对象进行分组的方法,使具有相似特征的对象**在一起,而具有不同特征的对象分开。它是机器学习和数据挖掘中常用的统计数据分析技术。探索性...

集群(cluster)和分层抽样(stratified sampling)的区别
聚类与分层抽样 调查在市场营销、健康和社会学领域的各种研究中都有应用。他们通常是采取一个人口样本,因为对整个人口进行调查将是昂贵的。除此之外,抽样使数据收集更快,因为它只关注人口的一小部分。保证了采集...

命名法(nomenclature)和分类(classification)的区别
...名法和分类法的区别是什么?主要区别的比较 关键术语 Classification, Nomenclature, Taxonomy, Scientific Names 什么是分类(classification)? 在生物学中,分类是科学家根据生物的相似性和不同性,将生物组织成一系列的群体和亚群体的过程...

分类(classification)和制表(tabulation)的区别
...现数据以便更容易解释和比较的方法称为制表法。分类(classification) vs. 制表(tabulation)分类和制表的区别在于,“分类”是指将数据分成不同的类别,制表是指将数据以表格形式列出。数据收集后分类,分类后制表。在收集数据的...
0 篇文章





