共分散の計算方法
共分散は、2つのデータセットの関係を理解するのに役立つ統計計算である。例えば、ある人類学者がある文化圏の人々の身長と体重を調査しているとします。調査対象者一人一人について、身長と体重は(x,y)のデータペアで表現することができる。これらの値を用いて、標準的な計算式で共分散関係を算出することができる。本稿では、まず、データセットの共分散を求める計算について説明する。その後、結果を見つけるためのさらに2つの自動化された方法について説明します...
方法1 4のうち方法1:標準的な計算式を使って共分散を手動で計算する。
- 1 標準的な共分散の公式とその構成要素を学ぶ。共分散の標準的な計算式は Σ(xi-xavg)(yi-yavg)/(n-1){displaystyleSigma (x_{i}-x_{text{avg})(y_{i}-y_{text{avg})/(n-1) } である。この式を使うには、これらの変数や記号の意味を理解する必要がある。 Σ{displaystyle Σ }この記号は、ギリシャ文字の「s」である。- このマークは、ギリシャ文字の "シグマ "です。数学の関数では、その後に続く一連のものを足し算することを意味します。この式でシグマ記号は、分数の分子に続く値を計算し、それらをすべて足して分母で割ることを意味しています。変数xi{displaystyle x_{i}}は "x sub "と読みます。- この変数は "x sub i "と読み、iの添え字はカウンターを表す。xavg{displaystyle x_{avg}} この変数は "x sub i "と読みます。- avg "は、x(avg)がすべてのx個のデータポイントの平均であることを意味します。平均値は、xに短い横線を引いて表記されることもある。yi{displaystyle y_{i}}- この変数は "y sub i "と読まれる。 iの添え字はカウンタを表す。yavg{displaystyle y_{avg}}- 「avg」は y(avg) がすべての y データポイントの平均であることを意味します。平均値は、短い横線を引いたYと表記されることもある。このスタイルでは、変数は'y-bar'として読まれるが、データセットの平均を意味する。 n{displaystyle n} - この変数はデータセット内のアイテムの数を表す。共分散の問題では、「項目」はx値とy値で構成されていることを思い出してください。 nの値はデータポイントの対数であり、単一の数字ではありません。
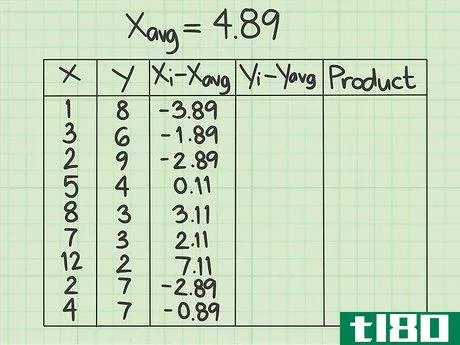
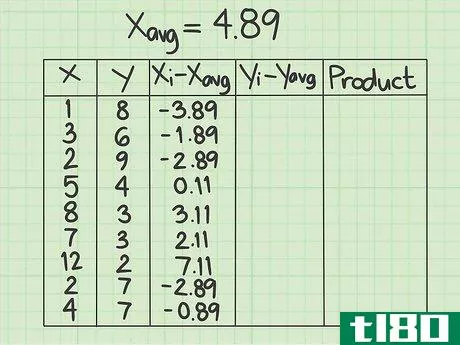
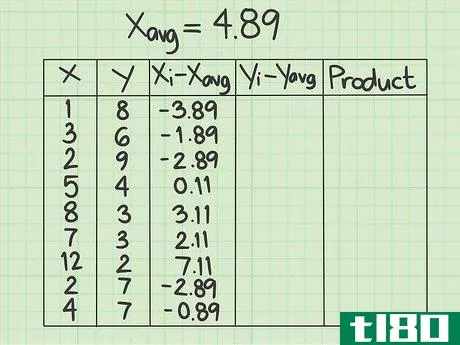
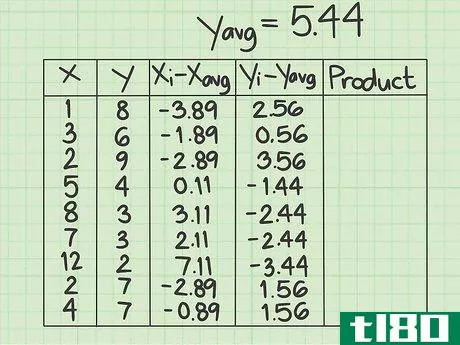
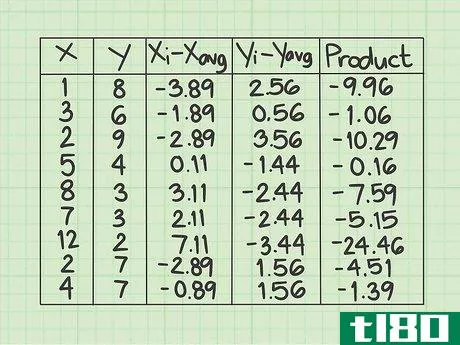
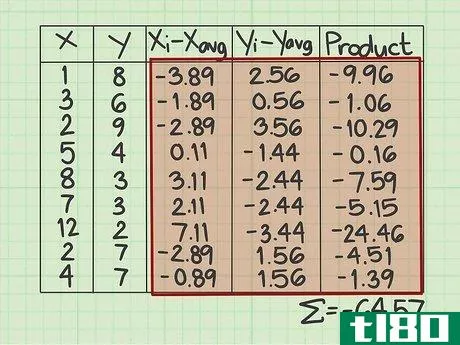
- 2 データシートをセットアップする。作業を開始する前にデータを収集しておくと便利です。5つの列からなる表を作成する必要があります。x{displaystyle x} - この列にはxデータポイントの値を記入します。 y{displaystyle y} - この列にはyデータポイントの値を記入します。y値と対応するx値との位置関係に注意してください。共分散の問題では、データ点の順番とxとyの組合せが重要である。(xi-xavg){displaystyle (x_{i}-x_{text{avg})}.- この欄は、はじめから空欄にしてください。(yi-yavg){displaystyle (y_{i}-y_{text{avg})} この列は最初は空欄にしておき、xデータポイントの平均を計算した後にデータで埋めます}。- この欄は最初から空欄にしてください。yデータポイントの平均を計算した後に、データで埋めることになります。Product{displaystyle {text{Product}}}最後の列も空欄にしてください。}- この最後の欄も空欄のままです。その都度、記入することになります。
- 3 X 個のデータ点の平均を計算する。このサンプルデータセットには9個の数字が含まれています。平均を求めるには、それらを足して合計を9で割ります。この結果、1+3+2+5+8+7+12+2+4=44となります。9で割ると平均は4.89となり、これが次の計算で使うx(avg)の値となる。
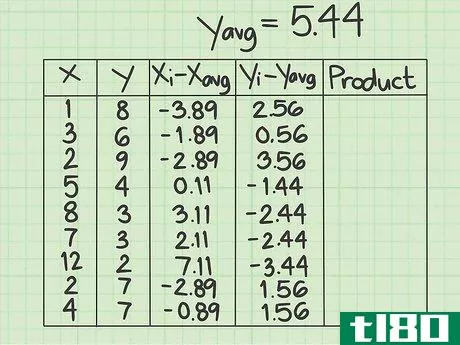
- 4 y データポイントの平均を計算する。ここでも、y列はxのデータポイントと重なる9つのデータポイントで構成されているはずです。これらのデータの平均を求めよ。このサンプルデータセットでは、8+6+9+4+3+3+2+7+7=49となり、この合計を9で割ると平均値は5.44となる。次の計算では、y(avg)の値を5.44とする。
- 5 (xi-xavg){displaystyle(x_{i}-x_{text{avg})} の値を算出する。x列の各項目について、その数値と平均値との差を求める必要があります。このサンプル問題では、各xデータポイントから4.89を引くことを意味します。元のデータポイントが平均より小さい場合、結果は負数になります。もし、元のデータポイントが平均より大きければ、結果は正の数になります。マイナス記号をしっかり把握すること。例えば、x列の最初のデータポイントは1です。 (xi-xavg){displaystyle (x_{i}-x_{text{avg})} 列の最初の行に入力する値は1-4.89、つまり-3.89です。各データポイントについてこのプロセスを繰り返します。2行目は3-4.89で-1.89、3行目は2-4.89で-2.89となる。この作業をすべてのデータポイントについて続ける。この列の9つの数字は、-3.89, -1.89, -2.89, 0.11, 3.11, 2.11, 7.11, -2.89, -0.89 とする。
- 6 (yi-yavg){displaystyle(y_{i}-y_{text{avg})} の値を算出する。このコラムでは、YデータポイントとY平均を使って、同様の減算を行います。もし、元のデータポイントが平均値より小さければ、結果はマイナスになります。もし、元のデータポイントが平均より大きければ、結果は正の数になります。マイナス記号を必ず記録してください。つまり、1列目は8-5.44で2.56、2列目は6-5.44で0.56となり、この列の9つの値は、2.56, 0.56, 3.56, -1.44, -2.44, -2.44, -3.44, 1.56, 1.56 と計算することになります。
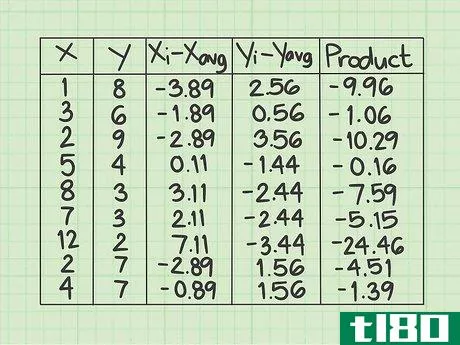
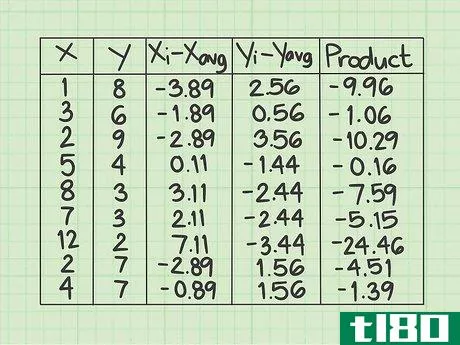
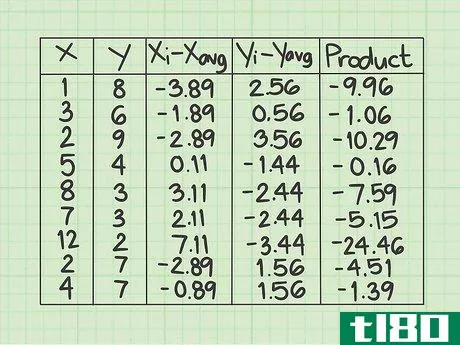
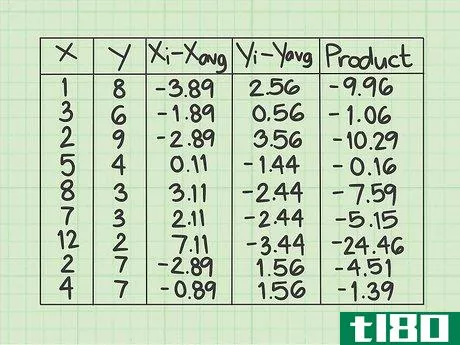
- 7 各データ行の積を計算する。最後の行には、前の2列で計算した数値 (xi-xavg) {displaystyle(x_{i}-x_{text{avg})} と (yi-yavg) {displaystyle(y_{i}-y_{text{avg})} を掛け合わせて記入します。 }} とします。一行ずつ丁寧に作業し、2つの数字を対応するデータポイントに掛け合わせる。ネガティブな兆候があれば、その都度記録してください。このデータサンプルの最初の行で、(xi-xavg){displaystyle (x_{i}-x_{text{avg})} の値 -3.89 と (yi-yavg){displaystyle (y_{i}-y_{text{avg})} の値 2.56 を計算します。これらの2つの数字の積は - になります。2行目は、2つの数値に-1.88*0.56=-1.06を掛けます。データセットが終了するまで、行ごとに掛け続けます。この欄の9つの値は、-9.96, -1.06, -10.29, -0.16, -7.59, -5.15, -24.46, -4.51, -1.39 となるはずです。
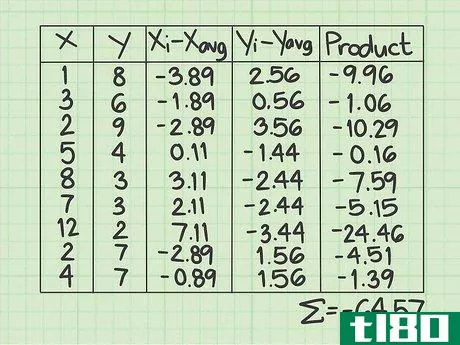
- 8 最後の列の値の合計を求めよ。そこで登場するのが "Σ "マークです。ここまでの計算をすべて行った後、結果を合算します。このサンプルデータセットでは、最後の列に9つの値があるはずです。この9つの数字を足し算してください。それぞれの数字が正の数なのか負の数なのか、よく注意してください。このサンプルデータセットでは、合計は-64.57となります。これは標準的な共分散式の分子の値を表している。
- 9 共分散の式の分母を計算する。標準共分散式の分子は、先ほど計算を終えた値です。分母は(n-1)で表され、これはデータセット内のデータペアの数より1つだけ少ない値である。
- 10 分母を分子で割る。共分散を計算する最後のステップは、分子であるΣ(xi-xavg)(yi-yavg){displaystyleSigma (x_{i}-x_{text{avg})(y_{i}-y_{text{avg})} を分母である (n-1){displaystyle (n-1)} で分割することである。この商がデータの共分散になります。このサンプルデータセットでは、この計算は-64.57/8となり、結果は-8.07となる。
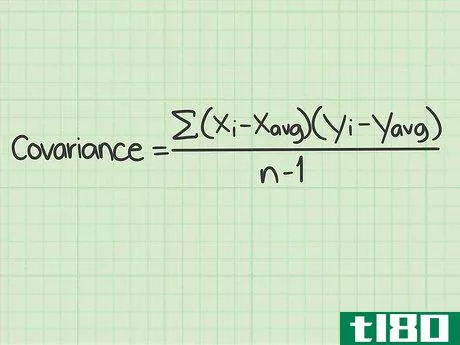
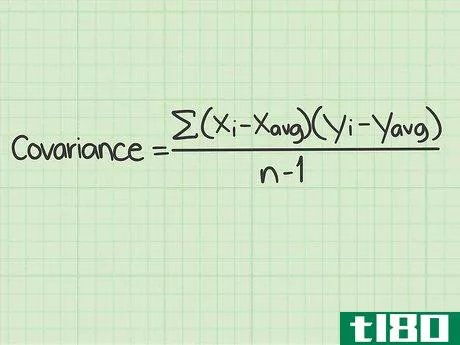
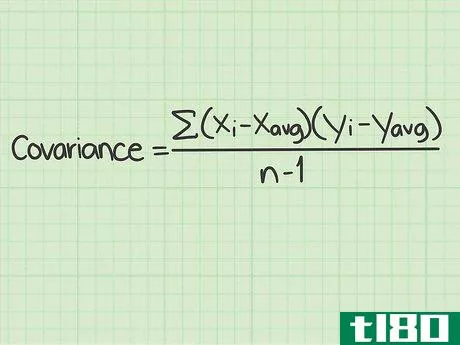
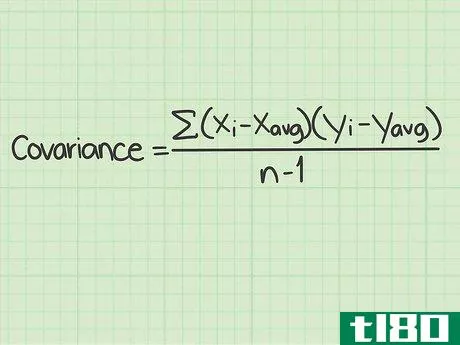
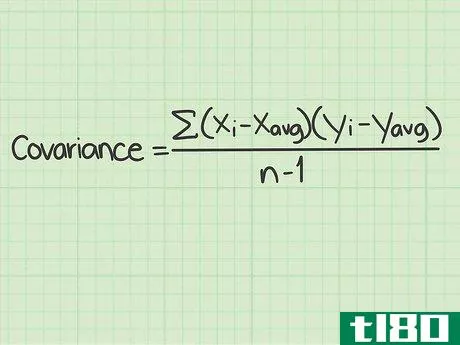
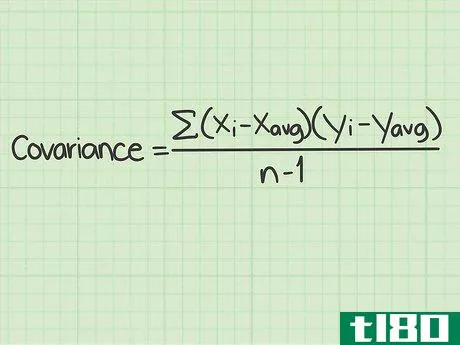
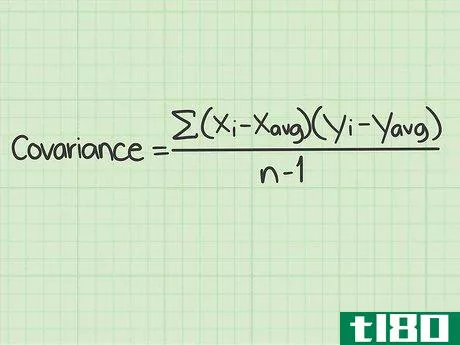
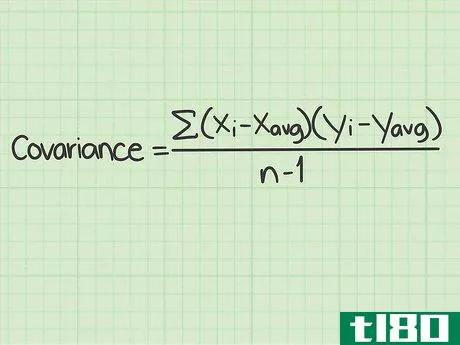








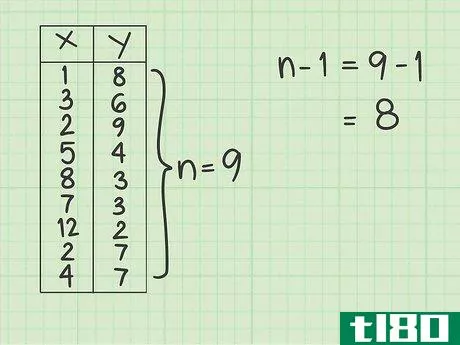



方法2 方法2/4:Excelの表計算ソフトを使った共分散の計算
- 1 繰り返しの計算にご注意ください。共分散は、何度か手計算をして、結果の意味を理解することが必要です。しかし、データの解釈において共分散値を頻繁に使用するのであれば、より速く、より自動で結果を得る方法を見つけたいものです。9組のデータという比較的小さなデータセットに対して、2つの平均を求め、18の別々の引き算、9の別々の掛け算、1つの足し算、そして最後に1つの割り算を行う計算であることに、もうお気づきでしょうか?これは、比較的小さな31個の計算で解決策を見つけることができるのです。その際、負の符号を落としたり、間違ってコピーしてしまい、結果を壊してしまう危険性があります。
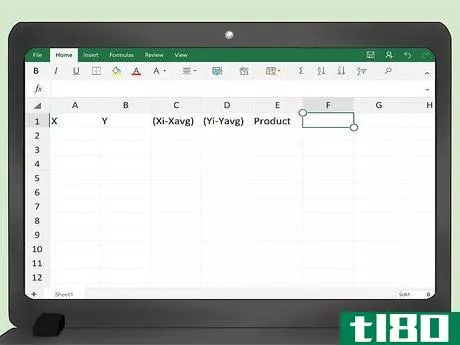
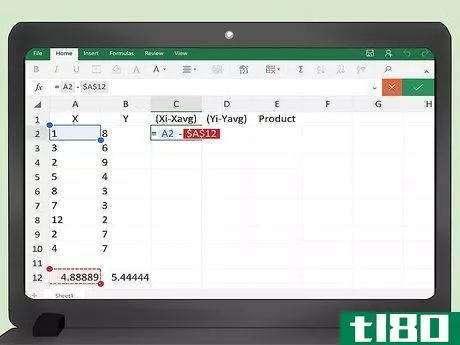
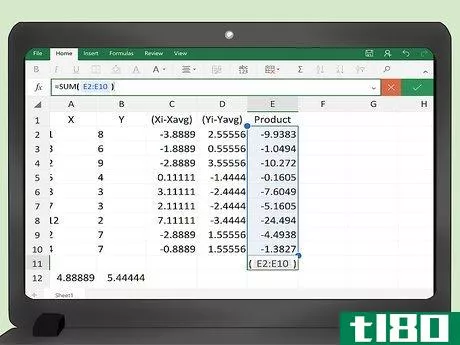
- 2 共分散を計算するためのスプレッドシートを作成する。Excel(または計算能力のある他の表計算ソフト)を使いこなせれば、共分散を求める表を簡単に作ることができる。5つの列の見出しに手計算でx, y, (x(i) - x(avg)), (y(i) - y(avg)), Productとラベルをつける。 ラベルを簡単にするために、データの意味を覚えていれば、3列目を「x-差」、4列目を「y-差」と呼んでも良いだろう。スプレッドシートを左上から始めると、セルA1がxのラベルとなり、他のラベルはセルE1までまたがることになります。
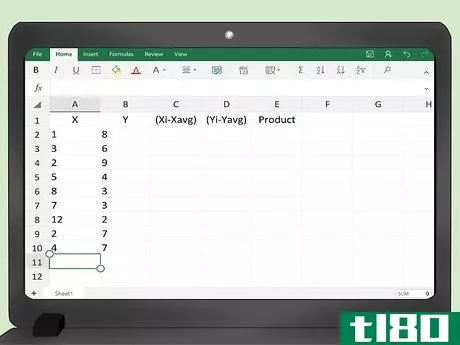
- 3 データポイントを記入する。xとyと書かれた2つの列にデータ値を入力します。データポイントの順序は重要なので、各Yを対応するXの値と一致させる必要があることを忘れないでください。x 値はセル A2 から始まり、必要なデータポイントまで続いていきます。
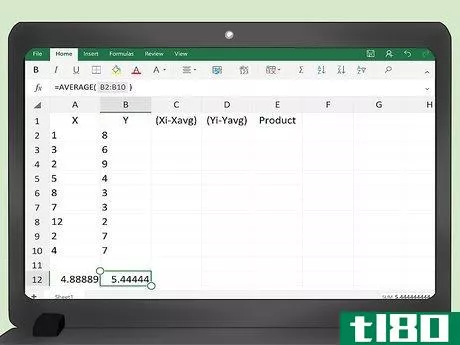
- 4 xとyの値の平均を求めます。エクセルがすぐに平均を計算してくれます。データの各列の下の最初の空いているセルに、数式 =AVG(A2:A___) を入力します。最後のデータポイントに対応するセル番号を空欄に記入する。例えば、100個のデータポイントがあれば、セルA2〜A101を埋めるので、=AVG(A2:A101)と入力します。Yデータの場合は、=AVG(B2:B101)の計算式を入力します。Excelでは、数式を=記号で始めることを覚えておいてください。
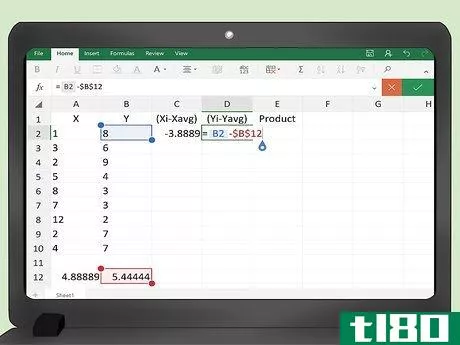
- 5 (x(i) - x(avg))列の計算式を入力します。セルC2には、最初の引き算を計算するための数式を入力する必要があります。この式は、= A2 - ____となる。xデータの平均値を含むセルのアドレスで空欄を埋めることになります。100個のデータポイントの例では、平均はセルA103になるので、数式は=A2-A103となります。
- 6 (y(i) - y(avg))のデータポイントについて上記の計算式を繰り返す。同じ例で、これはセルD2に入ります。数式は=B2-B103となります。
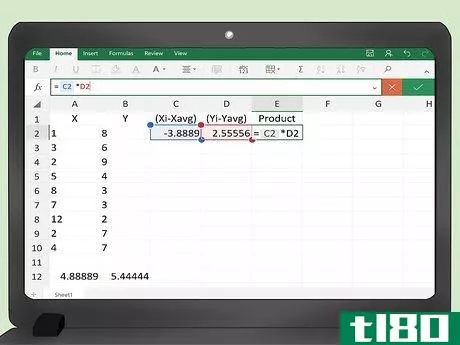
- 7 「製品」列の計算式を入力する。5列目のセルE2には、前の2つのセルの積を計算するための数式を入力する必要があります。これは、=C2*D2となる。
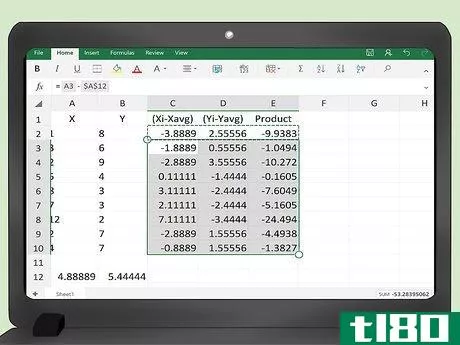
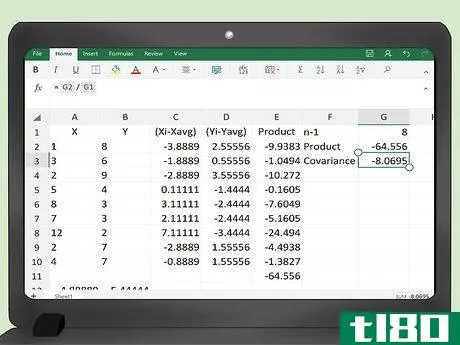
- 8 表を埋めるために数式を下にコピーします。ここまでは、2行目の最初のデータポイントのペアのみをプログラムしています。マウスを使って、セル C2、D2、E2 をハイライトします。次に、右下の小さなボックスにカーソルを合わせると、プラス記号が表示されます。マウスボタンをクリックし、押したままマウスを下にドラッグすると、ハイライトされたボックスがデータテーブル全体を埋めるように拡大されます。このステップでは、セルC2、D2、E2にある3つの数式が自動的に表全体にコピーされます。テーブルには、すべての計算結果が自動的に入力されているのが確認できるはずです。
- 9 最後の列の合計を計算する。商品」欄の項目の合計を求める必要があります。列の最後のデータポイントの下の空いているセルに、数式 =sum(E2:E___) を入力します。最後のデータポイントのセルアドレスで空白を埋める。100個のデータポイントの例では、この数式はセルE103に入ります。=sum(E2:E102) と入力することになります。
- 10 共分散を求めよ。また、最終的な計算はExcelに任せることもできます。最終的な計算結果は、この例ではセルE103にあり、共分散式の分子を表しています。このセルの下に、数式 = E103/___ を入力することができます。空欄にデータポイントの数を記入してください。この例では、これは100になります。結果は、データの共分散になります。
方法3 4のうち方法3:ウェブサイトの共分散計算機を利用する
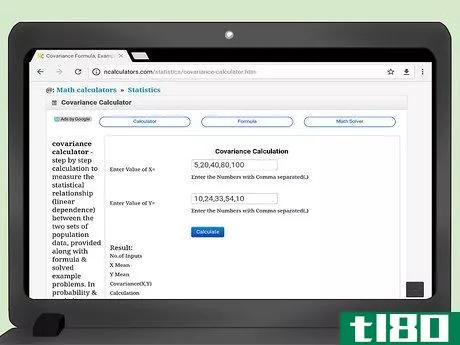
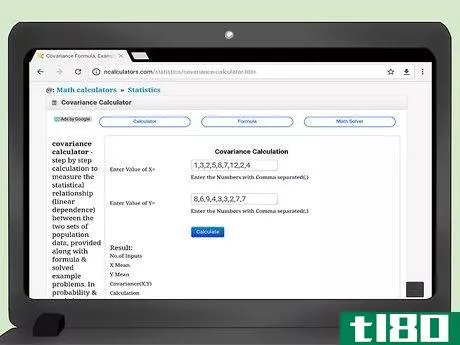
- 1 共分散計算機をインターネットで検索する。学校やプログラミング会社などが、共分散値を簡単に計算してくれるウェブサイトを作成しているところもあります。任意の検索エンジンで、「共分散計算機」と検索語を入力してください。
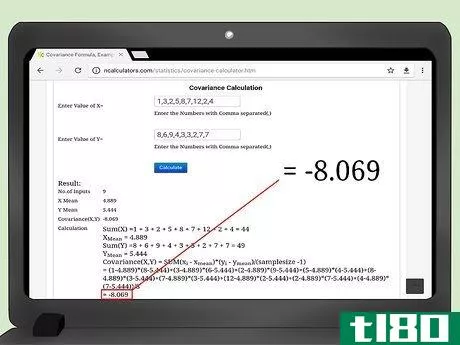
- 2 データを入力します。ホームページの説明をよく読んで、正しく入力してください。データペアが順番に並んでいることが重要です。そうでないと、共分散の結果が正しく表示されません。ウェブサイトによって、入力のスタイルが異なります。例えば、ウェブサイト(http://ncalculators.com/statistics/covariance-calculator.htm)には、X値を入力するための横長のボックスと、Y値を入力するための第二の横長のボックスがあります。用語はカンマだけで区切って入力するように言われます。したがって、この記事で先に計算したxデータセットは1,3,2,5,8,7,12,2,4と入力され、yデータセットは8,6,9,4,3,2,7,7となる。別のウェブサイトではhttps://www.thecalculator.co/math/Covariance-Calculator-705。htmlの場合、最初のボックスにxデータを入力するよう促されます。データは縦書きで、1行に1項目ずつ入力します。したがって、このサイトの入力は次のようになります:1325871224
- 3 結果を計算する。これらの計算サイトの魅力は、データを入力した後、一般的には「計算」ボタンをクリックするだけで、結果が自動的に表示されることです。ほとんどのサイトでは、x(平均)、y(平均)、nの中間計算が用意されています。
方法4 方法4:共分散の結果の解釈
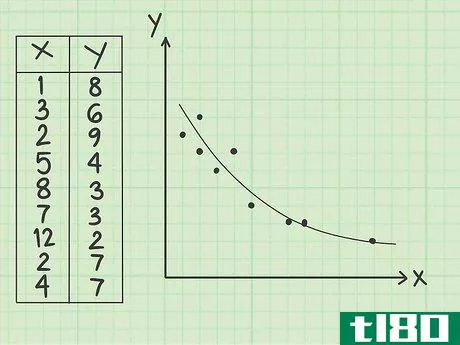
- 1 正または負の関係を見つける。共分散は、あるデータセットと別のデータセットの関係を示す一つの統計量である。冒頭で述べた例では、身長と体重の両方を測定しています。身長が伸びれば体重も増えるので、共分散の数値が正になることが予想されます。例えば、ゴルフの練習時間やスコアのデータを収集するとする。この場合、負の共分散を期待することになる。つまり、練習時間が増えればゴルフのスコアが下がるということだ。(ゴルフでは、スコアが低いほど良い)。上で計算したサンプルデータセットを考えてみましょう。これは、Xの値が大きくなると、Yの値が小さくなる傾向があることを意味します。実際、いくつかの値を見れば、そのことがわかるはずです。例えば、X値1と2はY値7、8、9に対応し、X値8、12はY値3、2とそれぞれ対になっている。
- 2 共分散の大きさを説明する。共分散スコアが大きな数値、つまり大きな正の数または大きな負の数であれば、2つのデータ要素が正または負のどちらかに強く関連していることを意味すると解釈できる。サンプルデータセットでは、共分散が-8.07とかなり大きめになっています。なお、データ値は1〜12まであるので、8はかなり高い数字です。これは、xとyのデータセットに強い関連性があることを示唆している。
- 3 関係性の欠如を理解する。共分散が0に等しいか、非常に近い値になった場合、データポイントは比較的相関がないと結論づけることができます。つまり、ある値の増加は、他の値の増加につながるかもしれないし、つながらないかもしれない。この2つの用語は、ほぼランダムにつながっています。例えば、靴のサイズとSATの点数を比較するとします。学生のSATスコアに影響を与える要因はたくさんあるので、共分散スコアは0に近くなると予想され、2つの値の間にはほとんど関連性がないことを示唆する。
- 4 関係をグラフで表示する。共分散を視覚的に理解するために、データポイントをX-Y座標平面上にプロットすることができます。そうすると、完全に直線上にはないものの、左上から右下への対角線に近い形で点が集まっていることが容易にわかるはずです。負の共分散を説明したものです。また、共分散の値が-8.07であることにも注目したい。これは、データ点と比較してかなり大きな数値である。この高い数値は、共分散がかなり大きいことを示し、データポイントの線形的な外観でこれを見ることができます。



- 2022-03-11 13:41 に公開
- 閲覧 ( 8 )
- 分類:教育