外れ値の算出方法
統計学では、外れ値とは、サンプル中の他のデータ点とは著しく異なるデータ点のことである。多くの場合、データセット内の外れ値は、統計学者に実験の異常や測定誤差を警告し、データセットから外れ値を省くことにつながる可能性があります。もし、データセットから外れ値を省いてしまうと、研究から導かれる結論が大きく変わってしまう可能性がある。このため、外れ値の計算方法や評価方法を知っておくことは、統計学を正しく理解するために重要である...
ステップス
- 1 潜在的な異常値を識別する方法を学ぶ。あるデータセットから外れ値を省くかどうかを決定する前に、まず、当然のことながら、データセット中の外れ値の可能性を特定する必要がある。一般に外れ値とは、データセット中の他の値が示す傾向とは大きく異なる、言い換えれば、他の値から外れたところにあるデータ点のことである。これは通常、データ表や(特に)グラフで簡単に見分けることができます。データセットをグラフで視覚的に表現する場合、異常値ポイントは他の値から「離れて」いることになる。例えば、データセットの大部分の点が直線を形成している場合、異常値はその直線に適合していると合理的に理解することはできない。ある部屋にある12種類の物体の温度を表すデータセットを考えてみよう。11個の物体が互いに華氏70度(摂氏21度)以内であっても、12個目の物体であるオーブンの温度が華氏300度(摂氏150度)であれば、ざっと調べただけでもオーブンが異常値であろうことがわかるだろう。
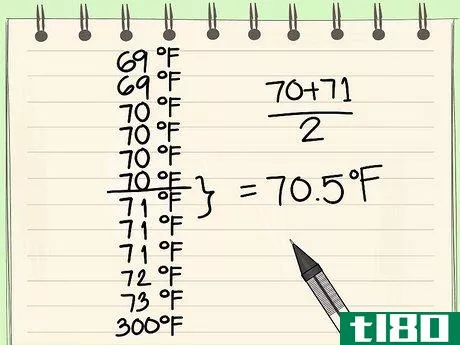
- 2 すべてのデータポイントを低いものから高いものへと並べる。データセットの外れ値を計算する場合、まずデータセットの中央値(median)を求めます。この作業は、データセット内の値を小さいものから大きいものの順に並べると、非常に簡単になる。したがって、先に進む前に、データセットの値をこのように並べ替えてください。上の例の続きを見てみましょう。ここに、部屋の中にあるいくつかの物体の温度を表すデータセットがあります。{71, 70, 73, 70, 70, 69, 70, 72, 71, 300, 71, 69}.データセットの値を低いものから高いものへと並べ替えると、新しい値のセットは次のようになります。{69, 69, 70, 70, 70, 70, 71, 71, 71, 72, 73, 300}.
- 3 データセットの中央値を算出する。データセットの中央値とは、データの半分が上にあり、半分が下にあるデータ点であり、基本的にはデータセットの「真ん中」の点である。これは、データセットに奇数のポイントが含まれている場合、簡単に見つけることができます。中央値は、その上下に同じ数のポイントを持つポイントです。ただし、偶数点の場合は、中点が1つではないので、中点の2点を平均して中央値を求めます。外れ値を計算するとき、中央値は通常変数Q2として指定されることに注意してください。これは、後で定義するように、Q1とQ3、すなわち下位四分位と上位四分位の間に位置するためです。偶数点のデータセットに惑わされないでください。真ん中の2点の平均は、データセット自体には現れない数値であることが多いのですが、それはそれでいいのです。しかし、真ん中の2点が同じ数字であれば、当然平均もその数字になり、それはそれでいいのです。この例では、12点です。したがって、このデータセットの中央値は、この2点の平均値である((70+71)/2), = 70.5である。
- 4 下位四分位を計算する。変数Q1に割り当てるこのポイントは、オブザベーションの25%(または1/4)が位置するデータポイントである。言い換えれば、これはデータセットの中で中央値より下にある点の中点である。中央値より下の値が偶数個ある場合は、中央値そのものを求める場合と同様に、2つの中間値を平均してQ1を求めなければならない。つまり、下位四分位を求めるには、下位6点のうち真ん中の2点を平均化する必要がある。下 6 点のうち 3 点目と 4 点目はともに 70 であるため、平均値は ((70+70)/2), = 70 となる。
- 5 上限四分位を計算する。この点を変数Q3とし、25%以上のデータが存在するデータ点とする。Q3の求め方はQ1の求め方とほぼ同じだが、この場合、中央値より下の点ではなく、中央値より上の点が考慮される。この2点を平均すると、((71+72)/2), = 71.5となり、71.5が問3の値となる。
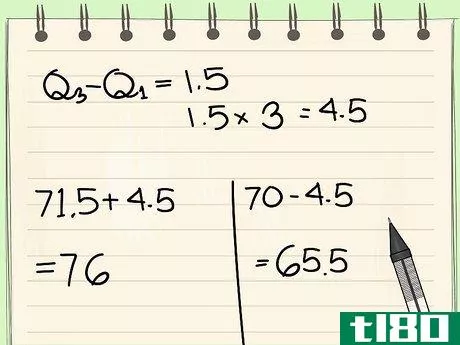
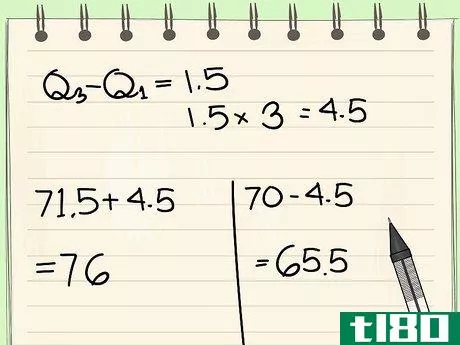
- 6 四分位範囲を求めなさい。さて、Q1 と Q3 を定義したので、この2つの変数の距離を計算する必要があります。Q1からQ3までの距離は、Q3からQ1を引くことで得られます。四分位範囲に得られる値は、データセット内の非外れ値の境界を決定するのに不可欠である。この例では、Q1 と Q3 の値はそれぞれ 70 と 71.5 である。四分位範囲を求めるには、Q3-Q1 を引く: 71.5 - 70 = 1.5 となる。例えば、Q1の値が-70であれば、四分位範囲は71.5 - (-70) = 141.5となり、これは正しい値です。
- 7 データセットの「内側のフェンス」を見つける。外れ値は、「内柵」「外柵」と呼ばれる一連の数値の境界線に含まれるかどうかを評価することで特定される。データセットの内部フェンスの外側にある点を小外れ値、外部フェンスの外側にある点を大外れ値として分類しています。データセットの内柵を求めるには、まず四分位範囲に1.5を掛け、その結果をQ3に加え、Q1から差し引く。この数字をQ3に加え、Q1から引くと、次のように内柵の境界が求まる: 71.5 + 2.25 = 73.7570 - 2.25 = 67.75 したがって、内柵の境界は 67.75 となる。このデータセットでは、オーブンの温度(300度)だけがこの範囲外にあるため、おそらく軽度の異常値であると考えられる。ただし、この温度が大きな異常値であるかどうかはまだ判断できないので、それまでは結論を出さないでおこう。
- 8 データセットの「外側の柵」を見つける。この例では、上記の四分位範囲に3をかけると、(1.5*3)、つまり4.5となります。 同じ方法で外枠の境界を求めます: 71.5 + 4.5 = 7670 - 4.5 = 65.5 外枠の境界は65.5と76です。外周フェンスの外側は、大きな異常値とみなされます。この例では、オーブンの温度が300度と外側のフェンスから大きく外れているので、大きな異常値であることは間違いありません。
- 9 外れ値を「捨てる」かどうかを判断するために定性的評価を用いる。以上の方法により、ある点が小さな外れ値なのか、大きな外れ値なのか、あるいは全く外れ値でないのかを判断することができる。しかし、間違いなく、異常値としてポイントを識別することは、単にデータセットから省略できる候補ポイントとしてマークするだけであり、必ず省略しなければならないポイントではありません。異常値を省略するかどうかを決めるには、異常値がデータセットの他の点と異なる理由が重要である。一般に、測定、記録、実験デザインのエラーなど、何らかのエラーに起因すると考えられる外れ値は省略されます。一方、誤差に起因しない外れ値で、予測できなかった新しい情報や傾向を明らかにするものは、通常、省略されることはない。また、外れ値がデータセットの平均値に大きな影響を与え、歪んだり誤解を招いたりしないかどうかも考慮すべき基準である。これは、データセットの平均値から結論を導き出すつもりなら、特に重要なことである。この例で評価してみましょう。この例では、予期せぬ自然の力によってオーブンの温度が300度に達したとは考えにくいので、オーブンのスイッチが誤って入り、異常な高温の測定値が出たとほぼ確実に結論づけることができます。さらに、外れ値を省略しない場合、データセットの平均は(69+69+70+70+71+72+73+300)/12=89.67度となるが、外れ値を省略した場合、平均は(69+69+70+70+71+72+73)/11=70。 55。 外れ値は、以下のようにすることができるので、外れ値を省略した場合、平均は(69+70+70+70+71+71+72+73)/11=70。この部屋の平均気温が90度近いというのは、ヒューマンエラーに起因するものであり、不正確であるため、異常値を省くことを選択すべきです。
- 10 外れ値を保持する(ことがある)ことの重要性を理解する。外れ値の中には、エラーに起因するものや、不正確または誤解を招くような方法で結果を歪めるものがあるため、データセットから除外されるべきものがある一方で、いくつかの外れ値は保持されるべきものです。例えば、異常値が真に得られたもの(つまり、誤った結果ではない)、および/または測定されている現象に何らかの新しい洞察を与えるものと思われる場合、それらは容易に省略されるべきではないでしょう。科学的な実験では、異常値を扱う際に特に注意が必要です。誤った異常値の省略は、何らかの新しい傾向や発見を示す情報の省略を意味する場合があります。例えば、養殖場の魚を大きくするための新薬を設計しているとします。以前のデータセット({71, 70, 73, 70, 69, 70, 72, 71, 300, 71, 69})を使いますが、今回は、各ポイントが、生まれてから別の実験薬で処置された後の魚の質量(グラム単位)を表します。つまり、1つ目の薬で71gの魚が、2つ目の薬で70gの魚が、といった具合に。この場合、300gはまだ大きな異常値ですが、誤差がないと仮定すれば、我々の実験の大きな成功を意味するので、省略すべきではありません。300gの魚が取れる薬は、他のどの薬よりも効果がありましたから、この点は、実は今回のデータセットの中で一番重要な点であり、最低の点ではないのです。









- 外れ値が見つかった場合、データセットから除外する前に、その存在を説明するようにしてください。外れ値は、測定エラーや分布の異常を指し示している可能性があります。
- 2022-03-11 15:07 に公開
- 閲覧 ( 21 )
- 分類:教育