如何正确设置机器人.txt为您的网站
如果你经营一个网站,你可能听说过机器人.txt文件(或“机器人排除标准”)。不管你有没有,现在是时候了解它了,因为这个简单的文本文件是你网站的关键部分。它可能看起来微不足道,但你可能会惊讶于它的重要性。

我们来看看机器人.txt文件是什么,它做什么,以及如何正确设置它为您的网站。
什么是一机器人.txt文件(a robots.txt file)?
了解机器人.txt文件工程,你需要知道一点关于搜索引擎。简短的版本是,他们发出“爬虫”,这是搜索互联网上的信息程序。然后,他们存储一些信息,以便日后指导人们使用。
这些爬虫,也被称为“机器人”或“蜘蛛”,从数十亿个网站上找到网页。搜索引擎会告诉他们去哪里的方向,但是个人网站也可以和机器人进行交流,告诉他们应该看哪些页面。
大多数时候,他们实际上在做相反的事情,告诉他们哪些页面不应该看。管理页面、后台门户、分类和标记页面,以及其他网站所有者不希望在搜索引擎上显示的内容。这些页面仍然对用户可见,并且任何有权限的人(通常是所有人)都可以访问它们。
但是通过告诉这些蜘蛛不要索引一些页面机器人.txt文件帮了大家一个忙。如果你在搜索引擎上搜索“MakeUseOf”,你会希望我们的管理页面在排名中排名靠前吗?不。那对任何人都没有好处,所以我们告诉搜索引擎不要显示它们。它还可以用来阻止搜索引擎签出可能无法帮助他们在搜索结果中对站点进行分类的页面。
总之,机器人.txt告诉网络爬虫该怎么做。
爬虫可以忽略吗机器人.txt?
爬虫会忽略吗机器人.txt文件夹?对。事实上,许多爬虫确实忽略了它。然而,一般来说,这些爬虫并不是来自著名的搜索引擎。他们来自垃圾邮件发送者,电子邮件收集者,和其他类型的自动机器人漫游互联网。记住这一点很重要——使用机器人排除标准来告诉机器人将其排除在外并不是一种有效的安全措施。事实上,有些机器人可能会从你告诉他们不要去的页面开始。
然而,搜索引擎会像你的机器人.txt文件说只要格式正确。
如何写一本书机器人.txt文件
机器人排除标准文件中有几个不同的部分。我在这里把它们一一分解。
用户代理声明
在告诉机器人不应该查看哪些页面之前,必须指定要与哪个机器人交谈。大多数情况下,您会使用一个简单的声明,意思是“所有机器人程序”。如下所示:
User-agent: *星号代表“所有机器人程序”。但是,您可以为某些机器人程序指定页面。要做到这一点,你需要知道你正在制定指导方针的机器人的名称。可能是这样的:
User-agent: Googlebot[list of pages not to crawl]User-agent: Googlebot-Image/1.0[list of pages not to crawl]User-agent: Bingbot[list of pages not to crawl]等等。如果你发现一个你根本不想爬网你的站点的机器人,你也可以指定它。
要查找用户代理的名称,请检查useragentstring.com[不再提供]。
不允许页面
这是robot排除文件的主要部分。通过一个简单的声明,您可以告诉一个bot或一组bot不要对某些页面进行爬网。语法很简单。以下是您如何禁止访问站点“admin”目录中的所有内容:
Disallow: /admin/那条线可以防止机器人爬行yoursite.com/管理员, yoursite.com/admin/login, yoursite.com/admin/files/secret.html以及属于admin目录下的任何其他内容。
要禁止单个页面,只需在“禁止”行中指定它:
Disallow: /public/exception.html现在“exception”页面将不会被绘制,但“public”文件夹中的其他所有内容都将被绘制。
要包含多个目录或页面,只需在后续行中列出它们:
Disallow: /private/Disallow: /admin/Disallow: /cgi-bin/Disallow: /temp/这四行将应用于您在本节顶部指定的任何用户代理。
如果您不想让机器人程序查看站点上的任何页面,请使用以下命令:
Disallow: /为机器人设定不同的标准
正如我们在上面看到的,您可以为不同的bot指定某些页面。结合前面的两个元素,下面是它的样子:
User-agent: googlebotDisallow: /admin/Disallow: /private/User-agent: bingbotDisallow: /admin/Disallow: /private/Disallow: /secret/“admin”和“private”部分在Google和Bing上是不可见的,但是Google会看到“secret”目录,而Bing不会。
您可以使用星号用户代理为所有bot指定常规规则,然后在后续部分中也为bot提供特定的说明。
把它们放在一起
有了以上知识,你就可以写一篇完整的文章了机器人.txt文件。只要启动你最喜欢的文本编辑器(我们是这里的超级粉丝),开始让机器人知道他们在你网站的某些地方不受欢迎。
如果你想看一个机器人.txt文件,只需前往任何网站并添加“/机器人.txt“坚持到底。这是巨型自行车的一部分机器人.txt文件:
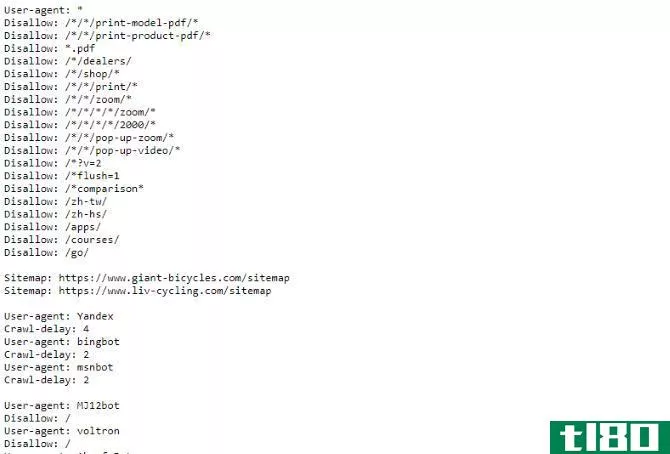
正如你所看到的,有相当多的页面,他们不想出现在搜索引擎上。他们还包括一些我们还没谈过的事情。让我们看看在robot排除文件中还可以执行哪些操作。
定位站点地图
如果你的机器人.txt文件告诉机器人不要去哪里,而你的站点地图则相反,并帮助他们找到他们要找的东西。虽然搜索引擎可能已经知道你的站点地图在哪里了,但再次让他们知道也无妨。
站点地图位置的声明很简单:
Sitemap: [URL of sitemap]就这样。
在我们自己的世界里机器人.txt文件,看起来是这样的:
Sitemap: https://www.makeuseof.com/sitemap_index.xml就这些。
设置爬网延迟
crawl delay指令告诉某些搜索引擎,它们可以多久索引一次站点上的页面。它以秒为单位,尽管有些搜索引擎对它的解释略有不同。有些人认为5的爬行延迟是告诉他们在每次爬行后等待5秒钟,以启动下一次爬行。另一些人则把它理解为每五秒钟只抓取一页的指令。
为什么你要告诉一个爬虫不要尽可能多地爬行?以保持带宽。如果您的服务器难以跟上流量,您可能需要设置爬网延迟。一般来说,大多数人不必为此担心。然而,大型高流量网站可能需要做一些试验。
下面是如何设置8秒的爬网延迟:
Crawl-delay: 8就这样。不是所有的搜索引擎都会遵守你的指令。但问也无妨。与禁止页面一样,您可以为特定搜索引擎设置不同的爬网延迟。
上传你的机器人.txt文件
设置好文件中的所有说明后,可以将其上载到站点。确保它是纯文本文件,并且具有机器人.txt. 然后上传到你的网站上,这样就可以在yoursite.com/机器人.txt文件。
如果你使用像WordPress这样的内容管理系统,你可能需要一种特定的方法来实现这一点。由于每个内容管理系统的内容不同,您需要查阅系统的文档。
一些系统可能也有上传文件的在线接口。对于这些,只需复制并粘贴在前面步骤中创建的文件。
记住更新你的文件
最后一条建议是偶尔检查一下你的机器人排除文件。你的网站改变了,你可能需要做一些调整。如果你注意到你的搜索引擎流量有一个奇怪的变化,那么也可以查看这个文件。标准符号也有可能在未来发生变化。就像你网站上的其他东西一样,每隔一段时间就可以查看一下。
你在网站上排除哪些页面的爬虫程序?你注意到搜索引擎流量有什么不同吗?请在下面分享您的建议和意见!
- 发表于 2021-03-13 06:21
- 阅读 ( 235 )
- 分类:编程
你可能感兴趣的文章

你的树莓皮有问题吗?试试这4个补丁
...较旧的Pi提供无线连接。但是一旦你启动了无线网络,你如何上网呢? ...

如何使用sweetfx获得令人惊叹的pc图形
... 如何激活sweetfx ...
如何创建自己的私有自托管ReadItLater应用程序
...恶意CSS和JS文件的危险。你也可以把你的档案列入黑名单机器人.txt文件保持私有。 ...

如何设置电子邮件在您的域免费与zoho邮件
...DNS传播,这可能需要几个小时。以下是DNS传播的含义以及如何检查其状态。 ...

10个有效的域名搜索工具和域名搜索工具
...有iOS和Android应用程序,Chrome扩展,Facebook Messenger和Slack的机器人程序。 ...

如何将raspberry pi设置为windows瘦客户端
...被称为瘦客户机,Raspberry Pi非常适合这项工作。下面介绍如何使用Raspberry Pi瘦客户端访问远程Windows桌面。 ...

超频覆盆子皮:如何做到这一点,你需要知道什么
...强大。但是你知道你可以从中榨取更多的能量吗?下面是如何超频你的树莓皮,并推动它比你想象的更远! ...

如何使用berryboot双引导树莓pi
... 如何获得berryboot和双启动你的覆盆子皮 ...
如何在heroku上免费托管python网站
... 现在让我们研究一下如何在Heroku上免费托管Python网站。注意,这是基于pythonversion3.7和Django version2.1.7的。 ...

如何使用amazon echo控制kodi media center
...我很怀疑,但很快就被打动了,渴望得到更多。 相关:如何设置和配置你的亚马逊回声 能够打开电视很酷,但我真正想要的是能够控制我的媒体中心。我想说“播放下一集的朋友”,让它搜索我的图书馆,看看我最后看了什么...
0 篇文章