你可能感兴趣的文章
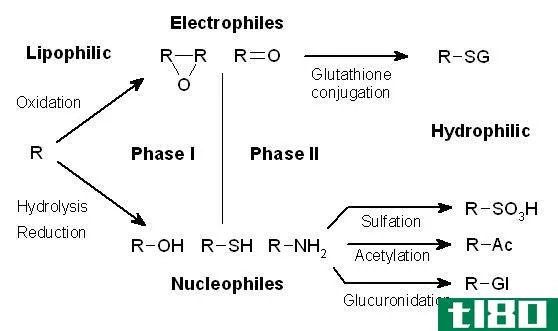
第一阶段(phase i)和ii期代谢(phase ii metabolism)的区别
第一阶段和第二阶段代谢的关键区别在于,第一阶段代谢将母体药物转化为极性活性代谢产物,而第二阶段代谢将母体药物转化为极性非活性代谢产物。 代谢(药物代谢)是生物体对药物的合成代谢和分解代谢。因此,药物...
rna聚合酶ⅠⅡ(rna polymerase i ii)和三(iii)的区别
关键区别——rna聚合酶i vs ii vs iii RNA聚合酶是一种重要的酶,存在于所有生物体和许多病毒中。它是一种在转录过程中从DNA模板合成RNA分子的酶。储存在DNA序列中的遗传信息被转换成mRNA序列,这个反应由RNA聚合酶酶催化。它...
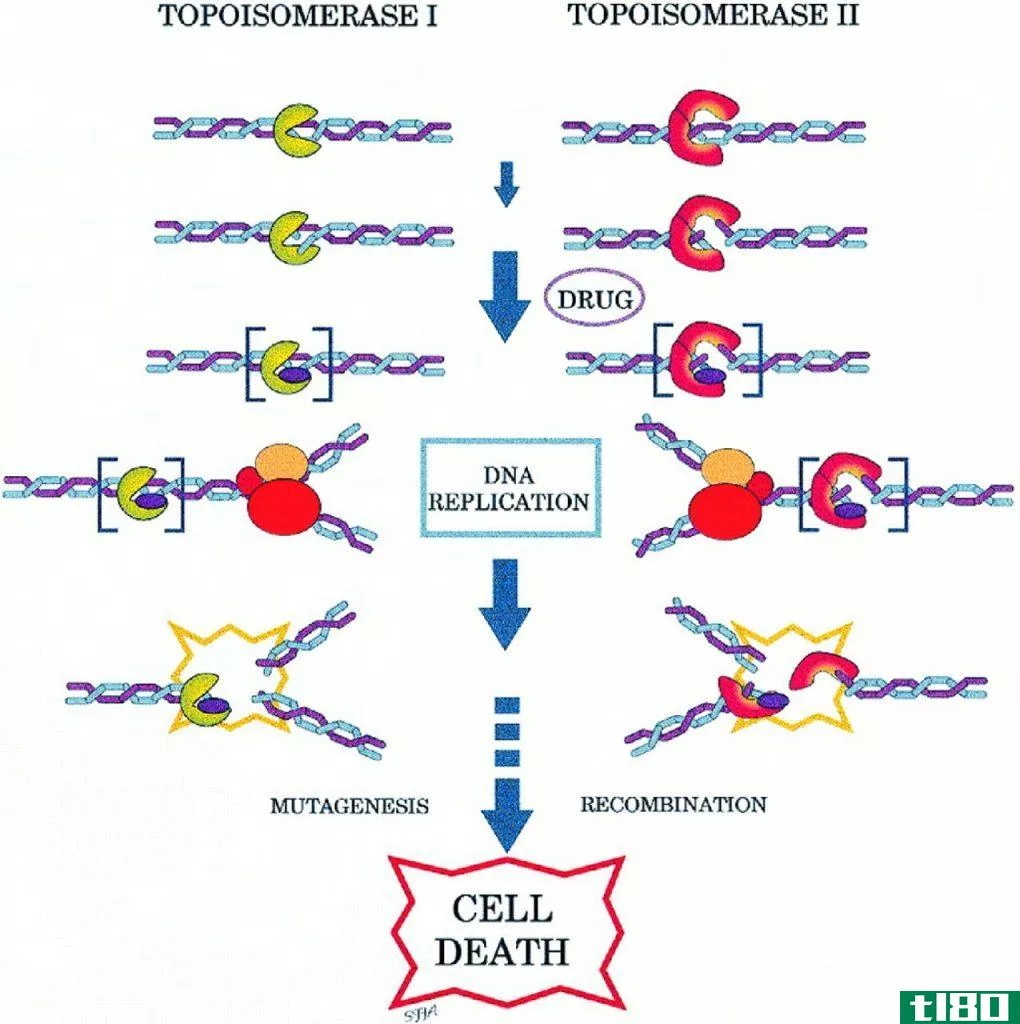
拓扑异构酶i(topoisomerase i)和二(ii)的区别
关键区别——拓扑异构酶i与ii 细胞分裂为两个子细胞需要DNA。DNA是通过DNA复制复制的。因此,应该有一种特殊的机制来复制高度损伤的螺旋DNA。拓扑异构酶是一种酶,它可以在特定的点切割DNA,并解开DNA的扭曲,缓解DNA的超...
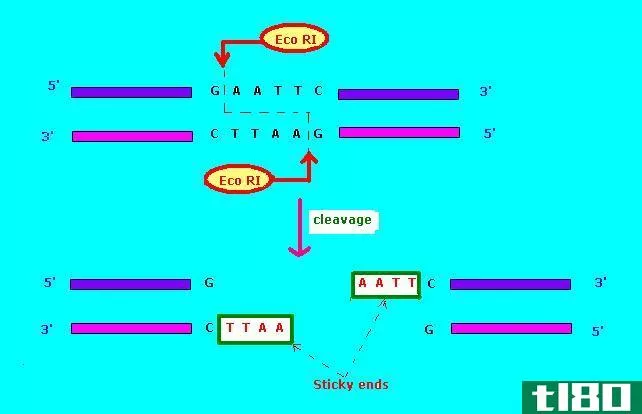
i型(type i)和Ⅱ型限制酶(type ii restriction enzyme)的区别
关键区别-i型与ii型限制性酶 限制性内切酶,通常被称为限制性内切酶,具有将DNA分子切割成小片段的能力。这个裂解过程发生在DNA分子的一个特殊识别位点附近或是一个叫做限制位点的位置。识别位点通常由4-8个碱基对组成...
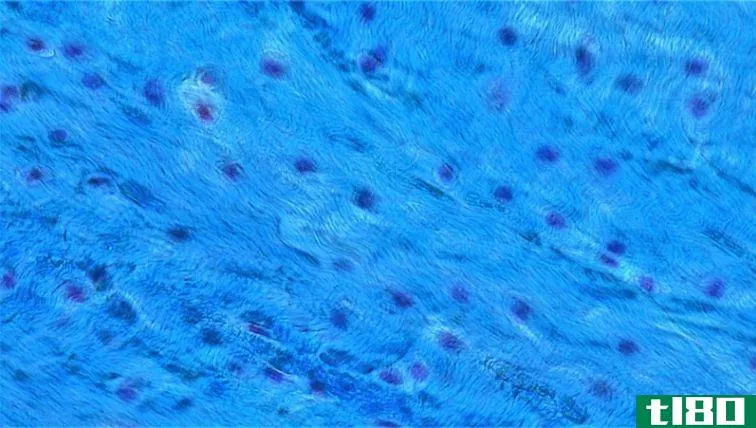
纤维软骨(fibrocartilage)和透明软骨(hyaline cartilage)的区别
纤维软骨和透明软骨的关键区别在于,纤维软骨是由透明软骨基质交替层和致密的I型和II型胶原纤维组成的最强的软骨,而透明软骨是由分布广泛的细II型胶原纤维组成的最弱的软骨。 软骨是一种结缔组织,存在于我们身体...
mhc i(mhc i)和二(ii)的区别
mhc i(mhc i)和二(ii)的区别 在免疫领域,主要组织相容性复合体(MHC)是抗原(异物)识别过程中的重要分子。它们被认为是一组细胞表面蛋白,基本上可以与外来抗原结合,在T细胞类型中呈现;T辅助细胞(TH)或细胞毒T细胞...
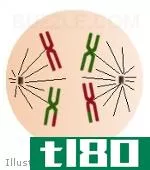
后期i(anaphase i)和后期ii(anaphase ii)的区别
后期I和后期II的关键区别在于,在后期I,同源染色体被分离并被拉向相反的两极,而在后期II,姐妹染色单体被分离并被拉向细胞的相反的两极。 有丝分裂和减数分裂是发生在细胞中的两种形式的核分裂。由于有丝分裂的结...
减数分裂Ⅰ(meiosis i)和减数分裂ii(meiosis ii)的区别
减数分裂I和减数分裂II的关键区别在于,减数分裂I是减数分裂的第一次细胞分裂,由一个二倍体细胞产生两个单倍体细胞,而减数分裂II是第二次细胞分裂,通过产生四个单倍体细胞完成减数分裂。 减数分裂是一个复杂的细...
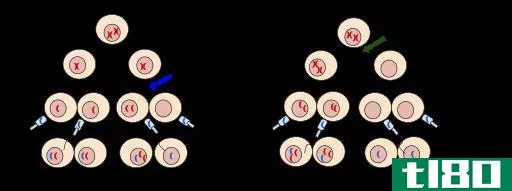
减数分裂1不分离(nondisjunction in meiosis 1)和2(2)的区别
...一个完美的过程,但在染色体分离的过程中,会以很小的错误率发生错误。这些错误称为非分离错误。不分离是指在有丝分裂和减数分裂过程中,同源染色体或姐妹染色单体不能或不能正确分离。在减数分裂Ⅰ期和减数分裂Ⅱ期...
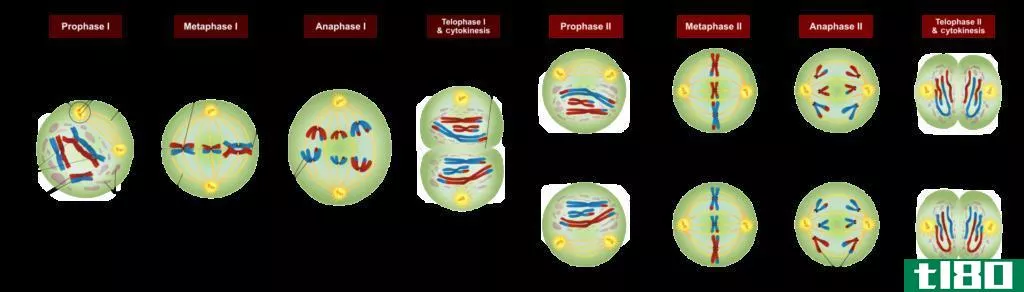
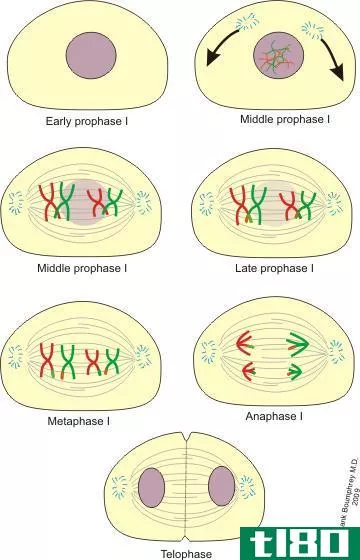
前期i(prophase i)和前期ii(prophase ii)的区别
前期Ⅰ与前期Ⅱ的关键区别在于,前期Ⅰ是减数分裂Ⅰ的开始阶段,在此之前有一个较长的间期,而前期Ⅱ是减数分裂Ⅱ的第一阶段,在此之前没有间期。 有丝分裂和减数分裂是生物体内两个重要的细胞分裂过程。减数分裂...
0 篇文章



{kind=link}