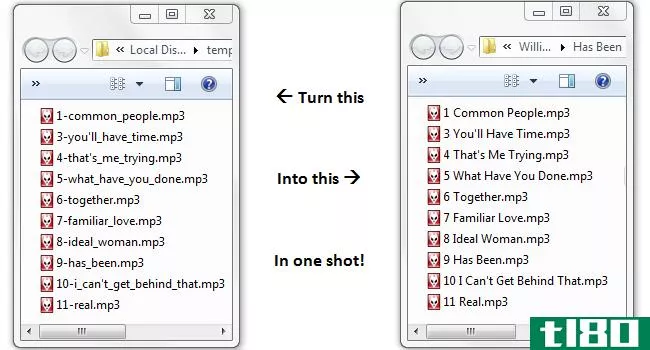
如何在linux上使用正则表达式(regex)
想知道那些奇怪的符号串在Linux上做了什么吗?他们给你命令行魔法!我们将教你如何施展正则表达式法术并提升你的命令行技能。
什么是正则表达式(regular expressi***)?
正则表达式(regex)是一种查找匹配字符序列的方法。它们使用字母和符号来定义在文件或流中搜索的模式。regex有几种不同的口味。我们将看看常见的Linux实用程序和命令中使用的版本,比如grep,一个打印匹配搜索模式的行的命令。
整本书都是关于regex的,所以本教程只是一个介绍。有基本正则表达式和扩展正则表达式,我们将在这里使用扩展正则表达式。
要在grep中使用扩展正则表达式,必须使用-E(extended)选项。因为这会很快变得令人厌烦,所以创建了egrep命令。egrep命令与grep-E组合相同,只是不必每次都使用-E选项。
如果你觉得使用白鹭更方便,你可以。不过,请注意,它已经被官方否决了。它仍然存在于我们检查过的所有发行版中,但将来可能会消失。
当然,你可以随时**你自己的别名,所以你喜欢的选项总是包括你。
相关:如何在Linux上创建别名和Shell函数
从小到大
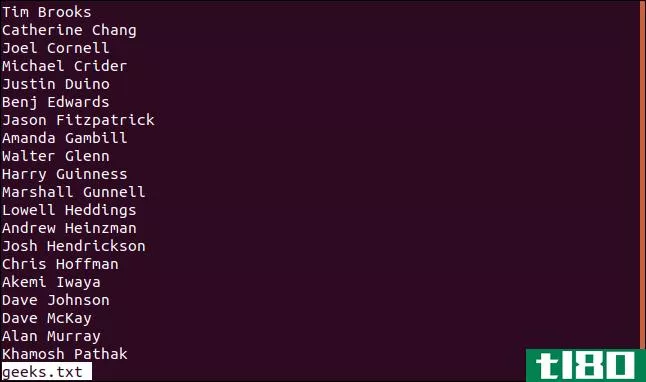
对于我们的示例,我们将使用一个包含极客列表的纯文本文件。记住,您可以将regex与许多Linux命令一起使用。我们只是使用grep作为一种方便的方式来演示它们。
以下是文件的内容:
less geek.txt
显示文件的第一部分。
让我们从一个简单的搜索模式开始,在文件中搜索字母“o”的出现处。同样,因为我们在所有示例中都使用了-E(扩展regex)选项,所以我们键入以下内容:
grep -E 'o' geeks.txt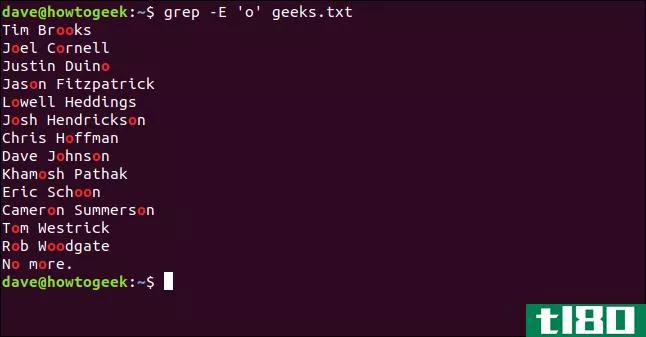
将显示包含搜索模式的每一行,并突出显示匹配的字母。我们执行了一个简单的搜索,没有任何限制。无论字母出现在字符串的末尾、同一个单词中出现两次,甚至出现在它自己旁边,都不重要。
有几个名字有双O;我们键入以下内容仅列出这些名字:
grep -E 'oo' geeks.txt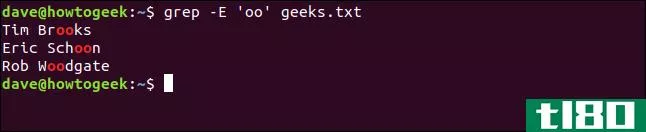
正如预期的那样,我们的结果集要小得多,而且我们的搜索词是按字面解释的。除了我们键入的字符外,它没有任何意义:双“o”字符。
我们将看到更多的功能与我们的搜索模式,因为我们前进。
行号和其他grep技巧
如果希望grep列出匹配条目的行号,可以使用-n(行号)选项。这是一个grep技巧,它不是regex功能的一部分。但是,有时您可能想知道匹配项在文件中的位置。
我们键入以下内容:
grep -E -n 'o' geeks.txt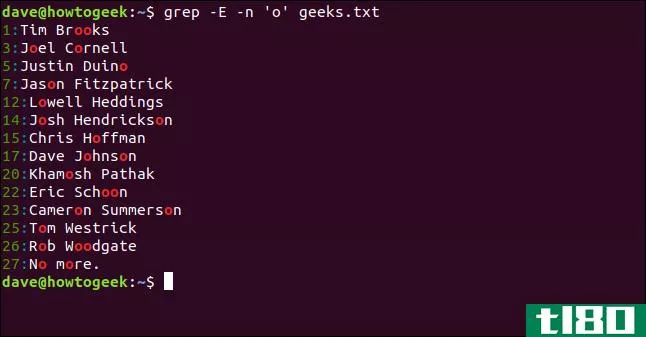
另一个方便的grep技巧是-o(仅匹配)选项。它只显示匹配的字符序列,而不显示周围的文本。如果您需要快速扫描列表中任何行上的重复匹配项,这将非常有用。
为此,我们键入以下内容:
grep -E -n -o 'o' geeks.txt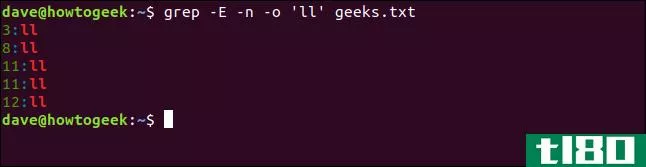
如果要将输出减少到最小值,可以使用-c(count)选项。
键入以下内容可查看文件中包含匹配项的行数:
grep -E -c 'o' geeks.txt
交替运算符
如果要同时搜索双“l”和双“o”,可以使用管道(|)字符,这是交替运算符。它将查找与其左侧或右侧搜索模式的匹配项。
我们键入以下内容:
grep -E -n -o 'll|oo' geeks.txt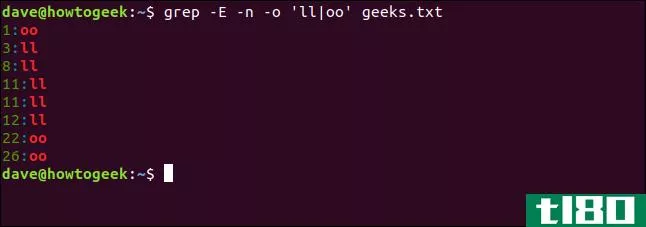
任何包含双“l”、“o”或两者的行都会出现在结果中。
区分大小写
您还可以使用alternation操作符创建搜索模式,如下所示:
am|Am这将同时匹配“am”和“am”。对于任何不重要的例子,这都会很快导致繁琐的搜索模式。解决这个问题的一个简单方法是在grep中使用-i(忽略大小写)选项。
为此,我们键入以下内容:
grep -E 'am' geeks.txt grep -E -i 'am' geeks.txt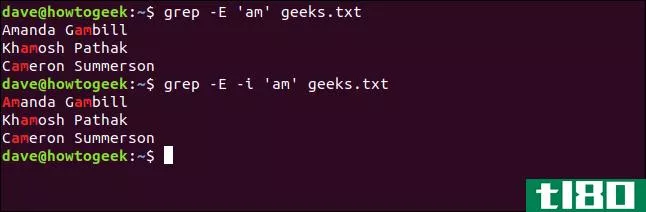
第一个命令生成三个结果,突出显示三个匹配项。第二个命令产生四个结果,因为“Amanda”中的“Am”也是匹配的。
锚定
我们也可以用其他方式匹配“Am”序列。例如,我们可以专门搜索该模式或忽略大小写,并指定序列必须出现在行首。
当匹配出现在一行字符或一个单词的特定部分的序列时,称为锚定。使用**符号(^)表示搜索模式只应将出现在行首的字符序列视为匹配。
我们键入以下内容(注意**符号在单引号内):
格雷普-E'Am'极客.txt
grep -E -i '^am' geeks.txt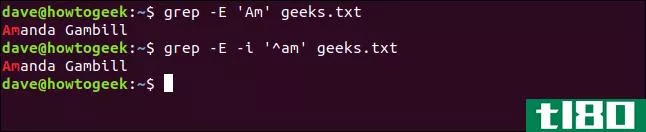
这两个命令都匹配“Am”
现在,让我们寻找在行尾包含双“n”的行。
我们键入以下内容,使用美元符号($)表示行尾:
grep -E -i 'nn' geeks.txt grep -E -i 'nn$' geeks.txt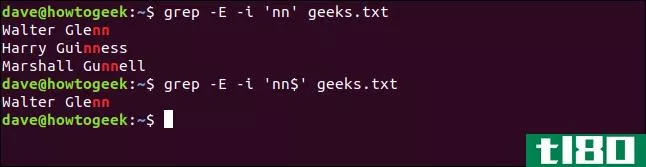
通配符
可以使用句点(.)表示任何单个字符。
我们键入以下内容来搜索以“T”开头、以“m”结尾、中间只有一个字符的模式:
grep -E 'T.m' geeks.txt
搜索模式与序列“Tim”和“Tom”匹配。您还可以重复句点以指示特定数量的字符。
我们键入以下内容表示我们不关心中间三个字符是什么:
grep-E 'J...n' geeks.txt
匹配并显示包含“Jason”的行。
使用星号(*)匹配前一个字符的零次或多次出现。在本例中,星号前面的字符是句点(.),也就是任何字符。
这意味着星号(*)将匹配任何字符出现的任何数目(包括零)。
星号有时会让regex新手感到困惑。这可能是因为他们通常将其用作通配符,表示“任何东西”
不过,在正则表达式中,'c*t'不匹配“cat”、“cot”、“coot”等,而是转换为“匹配零个或多个'c'字符,后跟一个't'。因此,它匹配“t”、“ct”、“cct”、“ccct”或任何数量的“c”字符。
因为我们知道文件中内容的格式,所以可以在搜索模式中添加空格作为最后一个字符。在我们的文件中,名字和姓氏之间只出现一个空格。
因此,我们键入以下命令强制搜索仅包含文件中的首个名称:
grep -E 'J.*n ' geeks.txt grep -E 'J.*n ' geeks.txt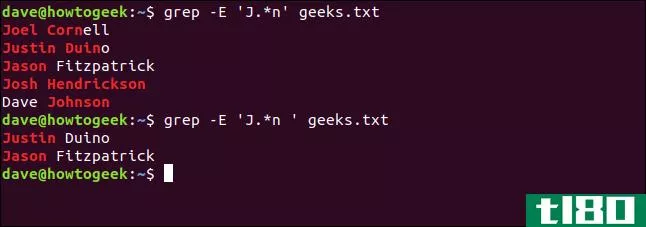
乍一看,第一个命令的结果似乎包含一些奇怪的匹配。但是,它们都符合我们使用的搜索模式的规则。
序列必须以大写字母“J”开头,后跟任意数量的字符,然后是一个“n”。尽管所有匹配项都以“J”开头,以“n”结尾,但其中一些并非您所期望的。
因为我们在第二个搜索模式中添加了空格,所以我们得到了我们想要的:所有以“J”开头以“n”结尾的名字
字符类
假设我们要找到所有以大写字母“N”或“W”开头的行
如果我们使用以下命令,它将匹配以大写“N”或“W”开头的序列的任何行,无论它出现在行中的何处:
grep -E 'N|W' geeks.txt那不是我们想要的。如果我们在搜索模式的开头应用行锚(^)的开头,如下所示,我们会得到相同的结果集,但原因不同:
grep -E '^N|W' geeks.txt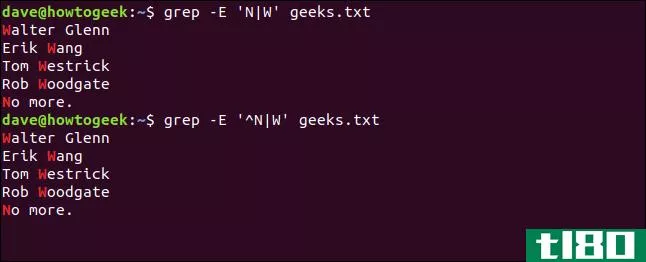
搜索匹配包含大写字母“W”的行。它还匹配“No more”行,因为它以大写“N”开头。行锚(^)的开头仅应用于大写“N”
我们还可以在大写字母“W”中添加一个起始线锚,但在比我们简单的示例更复杂的搜索模式中,这很快就会变得效率低下。
解决方案是将搜索模式的一部分括在括号([])中,并对组应用锚操作符。方括号([])表示“此列表中的任何字符”。这意味着我们可以省略(|)交替运算符,因为我们不需要它。
我们可以将行锚点的开始应用于括号([])中列表中的所有元素。(注意,锚索的起点在支架外)。
我们键入以下内容搜索以大写“N”或“W”开头的任何行:
grep -E '^[NW]' geeks.txt
我们也将在下一组命令中使用这些概念。
我们键入以下内容来搜索任何名为Tom或Tim的人:
grep -E 'T[oi]m' geeks.txt如果**符号(^)是方括号([])中的第一个字符,则搜索模式将查找列表中未出现的任何字符。
例如,我们键入以下内容以查找以“T”开头的任何名称,以“m”结尾,中间字母不是“o”:
grep -E 'T[^o]m' geeks.txt我们可以在列表中包含任意数量的字符。我们键入以下内容以查找以“T”开头、以“m”结尾、中间包含任何元音的名称:
grep -E 'T[aeiou]m' geeks.txt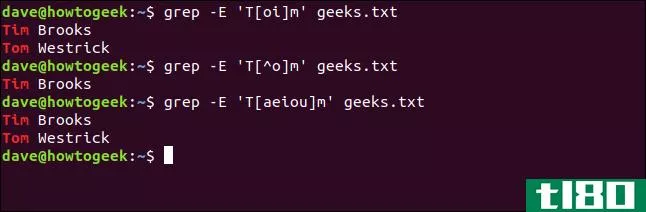
区间表达式
您可以使用间隔表达式指定希望在匹配字符串中找到前面的字符或组的次数。将数字括在大括号({})中。
一个数字本身就是那个数字的意思,但是如果你在后面加逗号(,),它就意味着那个数字或者更多。如果用逗号(1,2)分隔两个数字,则表示从最小到最大的数字范围。
我们要寻找以“T”开头,后跟至少一个但不超过两个连续元音,以“m”结尾的名字
所以,我们键入以下命令:
grep -E 'T[aeiou]{1,2}m' geeks.txt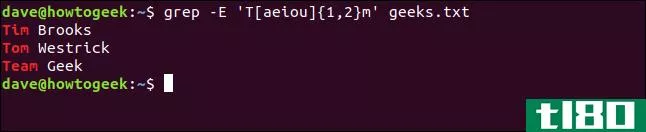
这与“Tim”、“Tom”和“团队”匹配
如果要搜索序列“el”,请键入以下内容:
grep -E 'el' geeks.txt我们在搜索模式中添加第二个“l”,以便只包含包含双“l”的序列:
grep -E 'ell' geeks.txt这相当于此命令:
grep -E 'el{2}' geeks.txt如果我们提供“l”的“至少一次且不超过两次”出现的范围,它将匹配“el”和“ell”序列。
这与这四个命令中的第一个命令的结果略有不同,其中所有匹配都是针对“el”序列的,包括“ell”序列中的那些序列(并且只突出显示了一个“l”)。
我们键入以下内容:
grep -E 'el{1,2}' geeks.txt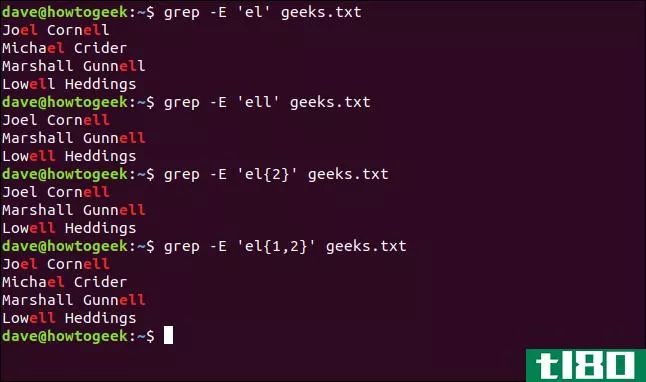
要查找两个或更多元音的所有序列,请键入以下命令:
grep -E '[aeiou]{2,}' geeks.txt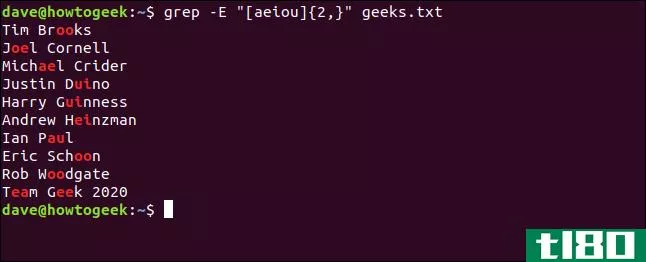
转义字符
假设我们想找出句点(.)是最后一个字符的行。我们知道美元符号($)是行尾锚点,因此可以键入以下内容:
grep -E '.$' geeks.txt
然而,如下所示,我们没有得到我们所期望的。
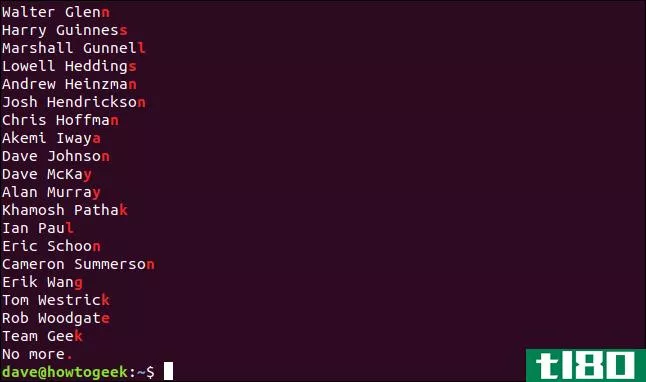
如前所述,句点(.)匹配任何单个字符。因为每一行都以一个字符结尾,所以每一行都在结果中返回。
那么,当您只想搜索实际字符时,如何防止特殊字符执行regex函数呢?为此,使用反斜杠(\)转义字符。
我们使用-E(扩展)选项的原因之一是,当您使用基本正则表达式时,它们需要的转义要少得多。
我们键入以下内容:
grep -e '\.$' geeks.txt
这与行末尾的实际句点字符(.)匹配。
锚定和文字
我们讨论了上面的起始(^)和行尾($)锚定。但是,您可以使用其他锚来操作单词的边界。
在此上下文中,单词是由空格(行首或行尾)限定的字符序列。所以,“psy66oh”可以算作一个词,尽管你在字典里找不到它。
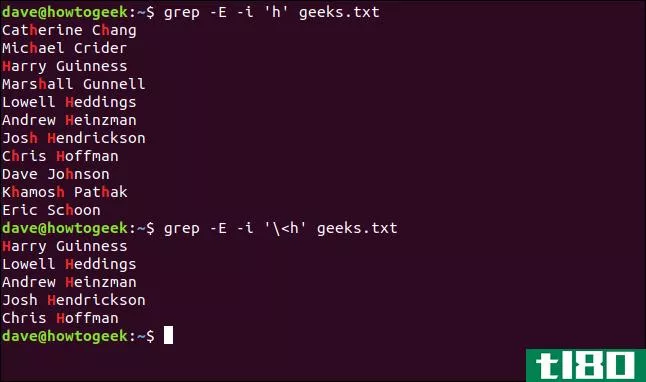
单词anchor的开头是(\<;);请注意,它指向左边,指向单词的开头。假设一个名字被错误地用小写输入。我们可以使用grep-i选项执行不区分大小写的搜索,并查找以“h”开头的名称
我们键入以下内容:
grep -E -i 'h' geeks.txt找到所有出现的“h”,而不仅仅是单词开头的。
grep -E -i '\<h' geeks.txt这只会在单词的开头找到。
让我们对字母“y”做一些类似的处理;我们只想看到它在单词末尾的例子。我们键入以下内容:
grep -E 'y' geeks.txt这将查找所有出现的“y”,无论它出现在单词中的何处。
现在,我们使用单词anchor(/>;)的结尾(指向右边或单词的结尾)键入以下内容:
grep -E 'y\>' geeks.txt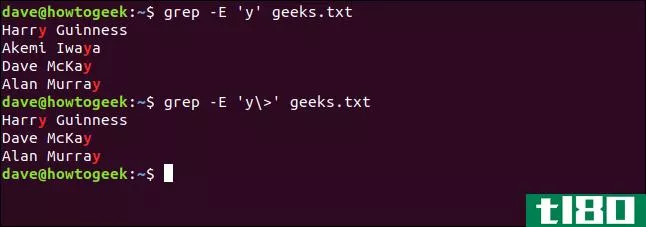
第二个命令生成所需的结果。
要创建查找整个单词的搜索模式,可以使用边界运算符(\b)。我们将在搜索模式的两端使用边界运算符(\B)来查找必须位于较大单词中的字符序列:
grep -E '\bGlenn\b' geeks.txt grep -E '\Bway\B' geeks.txt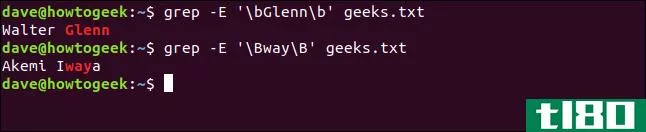
更多角色类
可以使用快捷方式指定字符类中的列表。这些范围指示符使您不必在搜索模式中键入列表的每个成员。
您可以使用以下所有选项:
- A-Z:从“A”到“Z”的所有大写字母
- a-z:从“a”到“z”的所有小写字母
- 0-9:从0到9的所有数字。
- d-p:从“d”到“p”的所有小写字母。这些自由格式样式允许您定义自己的范围。
- 2-7:从2到7的所有数字。
您还可以在搜索模式中使用任意数量的字符类。以下搜索模式匹配以“J”开头、后跟“o”或“s”、然后是“e”、“h”、“l”或“s”的序列:
grep -E 'J[os][ehls]' geeks.txt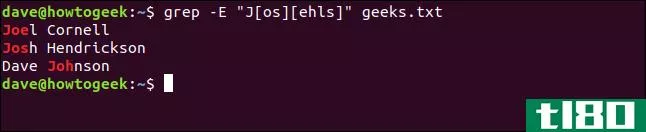
在下一个命令中,我们将使用a-z范围说明符。
我们的搜索命令是这样的:
- H:序列必须以“H”开头
- [a-z]:下一个字符可以是此范围内的任何小写字母。
- *:此处的星号表示任意数量的小写字母。
- 男:这个序列必须以“男”结尾
我们将所有这些放在下面的命令中:
grep -E 'H[a-z]*man' geeks.txt
没有什么是无法穿透的
一些正则表达式很快就很难直观地解析。当人们编写复杂的正则表达式时,通常会从小开始,添加越来越多的部分,直到它有效为止。随着时间的推移,他们的成熟程度会增加。
当你试着从最终版本向后看它做了什么,这是一个完全不同的挑战。
例如,查看以下命令:
grep -E '^([0-9]{4}[- ]){3}[0-9]{4}|[0-9]{16}' geeks.txt你从哪里开始解决这个问题?我们从头开始,一次只取一大块:
- ^:线锚的开始。所以,我们的顺序必须是第一个在线上。
- ([0-9]{4}[-]):括号将搜索模式元素**到一个组中。其他操作可以作为一个整体应用于此组(稍后将对此进行更多介绍)。第一个元素是一个字符类,它包含从零到九的数字范围[0-9]。然后,我们的第一个字符是一个从零到九的数字。接下来,我们有一个包含数字4{4}的区间表达式。这适用于我们的第一个字符,我们知道它将是一个数字。因此,搜索模式的第一部分现在是四位数。它可以后跟另一个字符类的空格或连字符([-])。
- {3} :包含数字3的间隔说明符,它紧随组。它应用于整个组,所以我们的搜索模式现在是四位数,后面是空格或连字符,重复三次。
- [0-9]:接下来,我们有另一个字符类,它包含从零到九的数字范围[0-9]。这将向搜索模式添加另一个字符,它可以是从零到九的任意数字。
- {4} :包含数字4的另一个间隔表达式应用于上一个字符。这意味着字符变成四个字符,所有字符都可以是从零到九的任意数字。
- |:交替操作符告诉我们它左边的一切都是一个完整的搜索模式,右边的所有东西都是一个新的搜索模式。因此,这个命令实际上是在搜索两种搜索模式中的任一种。第一组是三组四位数,后面是空格或连字符,然后是另外四位数字。
- [0-9]:第二个搜索模式以从零到九的任意数字开始。
- {16} :将间隔运算符应用于第一个字符,并将其转换为16个字符,所有字符都是数字。
因此,我们的搜索模式将查找以下任一项:
- 四组四位数字,每组之间用空格或连字符(-)分隔。
- 一组十六位数字。
结果如下所示。
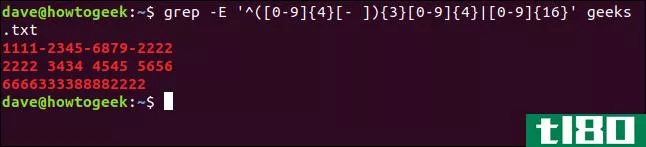
这种搜索模式正在寻找书写信用卡号的常见形式。它的多功能性也足以通过一个命令找到不同的样式。
慢慢来
复杂性通常只是简单的结合在一起。一旦您了解了基本的构建块,您就可以创建高效、强大的实用程序,并开发有价值的新技能。
- 发表于 2021-04-02 11:27
- 阅读 ( 223 )
- 分类:互联网
你可能感兴趣的文章

如何使用vim:基础指南
... 这里,regex是一个正则表达式。按n键进入下一场比赛,按n键进入上一场比赛。 ...
python regex初出茅庐的程序员备忘单
...行的现代编程语言之一。尽管学习起来很快,但它的正则表达式可能很棘手,特别是对于新手。 ...
如何在windows10上轻松批量重命名文件
...想用的旁边打个勾。以下是每个选项的作用: 使用正则表达式:这允许使用称为正则表达式的强大搜索字符串,它可以启用非常深入或复杂的搜索和替换操作。 区分大小写:此选项使搜索敏感,无论字母是大写还是小写。例如...

如何在linux上使用sed命令
...命令。然而,sed的模式匹配和文本选择功能严重依赖正则表达式(regex)。你需要熟悉这些才能充分利用sed。 相关:如何在Linux上使用正则表达式(regex) 一个简单的例子 首先,我们将使用echo通过管道向sed发送一些文本,并让se...
如何在linux上使用awk命令
...------"} $3 >= 1000 {print $1,$6}' /etc/passwd 模式是成熟的正则表达式,它们是awk的荣耀之一。 假设我们希望看到装载的文件系统的通用唯一标识符(uuid)。如果我们在/etc/fstab文件中搜索字符串“UUID”的出现,它应该会为我们返回...

如何在linux上使用grep命令
...一声。 kenthompson从ed编辑器(发音为eedee)中提取了正则表达式搜索功能,并为自己创建了一个小程序来搜索文本文件。他在贝尔实验室的部门负责人道格·麦克罗伊(Doug Mcilroy)找到汤普森,描述了他的一位同事李·麦克马洪(L...

如何使用linux cat和tac命令
...分隔符。 r(regex)选项告诉tac将分隔符字符串视为正则表达式。 -b(before)选项使tac将分隔符列在每条记录之前而不是之后(这是默认分隔符换行符的通常位置)。 -s(分隔符)字符串^=SEQ.+[0-9]+*$被破译如下: ^字符表示行的开...
如何在linux上使用rename命令
...第二个术语(.prg)将被替换。 命令的中间部分,即中心表达式,是一个Perl“正则表达式”,它使rename命令具有了灵活性。 更改文件名的其他部分 到目前为止,我们已经更改了文件扩展名,让我们修改文件名的其他部分。 目录...

如何使用基本正则表达式更好地搜索和节省时间
...的方法来完成你的工作。谢天谢地,有,它被称为“正则表达式” (漫画来自XKCD.com网站) 什么是正则表达式(regular expressi***)? 正则表达式是以非常特定的方式格式化的语句,可以代表许多不同的结果。也称为“regex”或“regex...
shell脚本初学者指南3:更多基本命令和链
...这是Linux中最强大、最有用的命令之一。它代表全局/正则表达式打印。它浏览一个文件并打印与特定模式匹配的任何行。因为这个模式是基于“正则表达式”的,所以一条简洁的行可以产生大量要匹配的模式。不过,对于not,您...
0 篇文章