如何使用bash从subreddit中获取主题列表
Reddit为每个subreddit提供JSON提要。下面是如何创建一个Bash脚本,从您喜欢的任何subreddit下载并解析帖子列表。这只是Reddit的JSON提要可以做的一件事。
安装卷曲和jq
我们将使用curl从Reddit和jq获取JSON提要,解析JSON数据并从结果中提取所需的字段。在Ubuntu和其他基于Debian的Linux发行版上使用apt-get安装这两个依赖项。在其他Linux发行版上,请改用发行版的包管理工具。
sudo apt-get install curl jq从reddit获取一些json数据
让我们看看数据提要是什么样子的。使用curl从MildlyInteresting subreddit获取最新帖子:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json注意URL:-s之前使用的选项是如何强制curl在静默模式下运行的,这样除了Reddit服务器上的数据外,我们就看不到任何输出了。下一个选项和后面的参数,-A“reddit scraper example”设置一个自定义用户代理字符串,帮助reddit识别访问其数据的服务。redditapi服务器基于用户代理字符串应用速率限制。设置一个自定义值将导致Reddit将我们的速率限制与其他调用者分开,并减少出现http429速率限制超出错误的可能性。
输出应该填满终端窗口,如下所示:
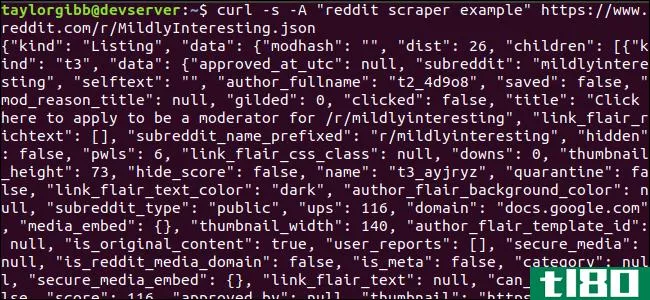
输出数据中有很多字段,但我们感兴趣的只是标题、永久链接和URL。您可以在Reddit的API文档页面上看到类型及其字段的详尽列表:https://github.com/reddit-archive/reddit/wiki/JSON
从json输出中提取数据
我们要从输出数据中提取Title、Permalink和URL,并将其保存到一个以制表符分隔的文件中。我们可以使用sed和grep这样的文本处理工具,但是我们还有另一个可以理解JSON数据结构的工具,称为jq。在我们的第一次尝试中,让我们使用它来漂亮地打印输出并对输出进行颜色编码。我们将使用与前面相同的调用,但是这次,通过jq管道输出并指示它解析和打印JSON数据。
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq .注意命令后面的句点。这个表达式只是解析输入并按原样打印。输出的格式和颜色很好:
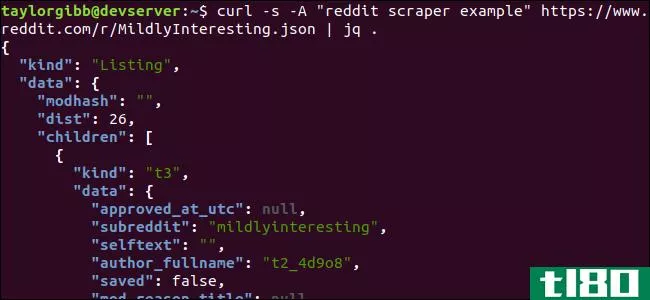
让我们检查一下从Reddit返回的JSON数据的结构。根结果是一个包含两个属性的对象:kind和data。后者拥有一个名为children的属性,其中包含一个指向此子reddit的post数组。
数组中的每个项都是一个对象,它还包含两个名为kind和data的字段。我们要获取的属性在数据对象中。jq需要一个可以应用于输入数据并产生所需输出的表达式。它必须描述内容的层次结构和数组的成员资格,以及数据应该如何转换。让我们用正确的表达式再次运行整个命令:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’输出在各自的行上显示标题、URL和永久链接:
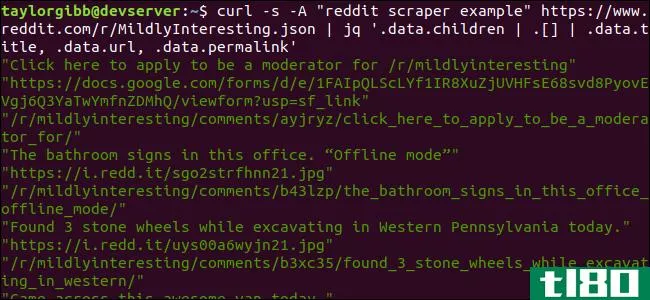
让我们深入到我们称之为jq的指挥部:
jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’此命令中有三个表达式,由两个管道符号分隔。每个表达式的结果都会传递给下一个表达式进行进一步计算。第一个表达式过滤除Reddit列表数组之外的所有内容。此输出通过管道传输到第二个表达式中,并强制输入到数组中。第三个表达式作用于数组中的每个元素并提取三个属性。关于jq及其表达式语法的更多信息可以在jq的官方手册中找到。
把这些都写进剧本里
让我们把API调用和JSON后处理放在一个脚本中,这个脚本将生成一个包含我们想要的post的文件。我们将添加对从任何subreddit获取帖子的支持,而不仅仅是/r/MildlyInteresting。
打开编辑器,将此代码段的内容复制到名为scrape的文件中-reddit.sh公司
#!/bin/bash if [ -z "$1" ] then echo "Please specify a subreddit" exit 1 fi SUBREDDIT=$1 NOW=$(date +"%m_%d_%y-%H_%M") OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt" curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json | \ jq '.data.children | .[] | .data.title, .data.url, .data.permalink' | \ while read -r TITLE; do read -r URL read -r PERMALINK echo -e "${TITLE}\t${URL}\t${PERMALINK}" | tr --delete \" >> ${OUTPUT_FILE} done此脚本将首先检查用户是否提供了subreddit名称。否则,它将退出并返回一条错误消息和一个非零返回代码。
接下来,它将第一个参数存储为subreddit名称,并建立一个带有日期戳的文件名来保存输出。
当使用自定义头和要刮取的子reddit的URL调用curl时,操作开始。输出通过管道传输到jq,在jq中解析并简化为三个字段:Title、URL和Permalink。这些行一次读取一行,然后使用read命令保存到一个变量中,所有这些行都在while循环中,该循环将一直持续到没有其他行可读取为止。内部while块的最后一行回显由制表符分隔的三个字段,然后通过tr命令传递它,以便可以去掉双引号。然后将输出附加到文件。
在执行此脚本之前,必须确保已授予它执行权限。使用chmod命令将这些权限应用于文件:
chmod u+x scrape-reddit.sh最后,使用subreddit名称执行脚本:
./scrape-reddit.sh MildlyInteresting输出文件在同一目录下生成,其内容如下所示:
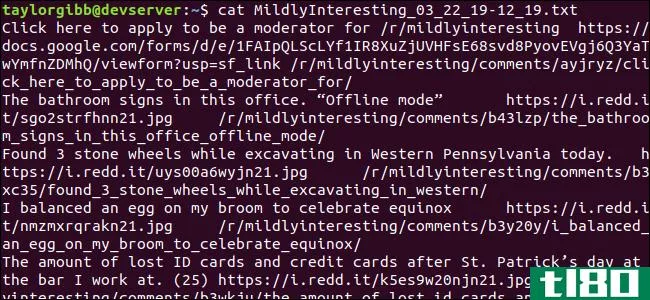
每行包含我们要查找的三个字段,用制表符分隔。
更进一步
Reddit是一个有趣的内容和媒体的金矿,使用它的jsonapi很容易访问。现在您有了访问这些数据和处理结果的方法,您可以执行以下操作:
- 从/r/WorldNews获取最新的标题,并使用notify send将它们发送到您的桌面
- 将/r/dadJones中最好的笑话集成到系统的每日消息中
- 从/r/aww获取今天的最佳图片,并将其作为桌面背景
使用提供的数据和系统上的工具,所有这些都是可能的。快乐黑客!
- 发表于 2021-04-03 18:06
- 阅读 ( 208 )
- 分类:互联网
你可能感兴趣的文章

2021年面向开发者、云工程师和devops的5大linux课程
... 本课程将带您了解Linux的“如何”和“为什么”,并展示各种Linux命令的工作方式、它们的真实结构以及记住这些命令的正确方法。 ...

忘记默认的子项:改为订阅这7个备选方案
... 但您不太可能从一开始就拥有订阅的默认subreddits的体验。让我们来谈谈为什么它们通常都很糟糕,最好的subredits你应该遵循。 ...

使用linux进行编程的7个绝佳理由
...为程序员和极客的天堂。我们已经写了很多关于操作系统如何适合从学生到艺术家的每个人的文章,但是是的,Linux是一个很好的编程平台。无论您是考虑到开放精神还是整个生态系统,都有很多理由考虑让Linux成为您编写代码...

5个应用程序和网站,找到reddit的最佳帖子和最喜欢的推荐
Reddit有那么多人在这么多subreddit上谈论这么多事情。你怎样才能轻易地得到最好的推荐?嗯,有一些网站和应用程序收集了Reddit的精华。 ...

找到值得玩的新手机游戏的7种方法
... Android和iOS都有自己的subreddits,它们是各种应用程序(包括****)的推荐和交易宝库。他们有一个活跃的追随者与成千上万的订户谁张贴相当定期。这些主题涵盖了从一般汇编到技巧和窍门,您...

如何使用applescript将bash脚本转换为可单击的应用程序
...为输入运行它。这些特殊的应用程序被称为水滴。下面是如何创建一个: ...

reddit是什么?它是如何工作的?
...Reddit是一个巨大的网站,但它被分成数千个小社区,称为subreddits。subreddit只是一个专门讨论特定主题的董事会。每一个都以reddit.com/r/,例如reddit.com/r/任天堂交换机. 在大多数情况下,subreddit有自己的主题、规则和期望。 ...
如何在windows10上获得linux bash shell
... 如何在windows10上安装linux bash shell ...

如何定制mac终端并使其更有用
...个新手,现在坚持默认的bashshell是可以的。但你应该知道如何在需要的时候切换它们。 ...

关于linux中bash for loops的所有知识
... 第一行告诉运行这个程序的人如何运行它(即使用bash解释器)。第二个命令与您在命令行中输入的任何其他命令一样。将该文件另存为hello_世界.sh,然后: ...
0 篇文章