你可能感兴趣的文章
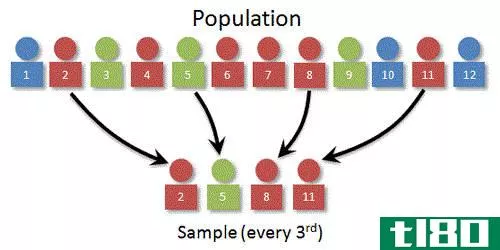
人口(population)和样品(sample)的区别
人口与样本 “人口”一词只是指一个地方或领土上同一物种的身体或总人数,无论是一个国家、城市、州或任何地区或地区。它也可能与特定种族或阶级有关。这方面的一个例子是土著人口或学生人口。人口可以是小的,也可...

例子(example)和样品(sample)的区别
...西,他们所代表的。然而,例子往往是用视觉或观察。当代表性零件在给定的情况下不可能重新创建或重建时,也可以使用它们。 另一方面,样本只是更大事物的一小部分。与示例不同,示例是随机的,而不是特定的。样本通...
定性的 分析(qualitative analysis)和定量分析(quantitative analysis)的区别
...在定性分析中,数据以非结构化的方式收集在小的、不具代表性的样本中。收集的典型数据包括肤色、种族、宗教、国籍等等。另一方面,在定量分析中,数据收集在大的、有代表性的样本中,可以概括整个人群。 定性和定量...

人口(population)和样品(sample)的区别
...群进行测试,结果是真实的意见代表,而如果选择了不具代表性的样本,结果有一定的误差。结论综上所述,样本是从人群中挑选出来的一小群单位,他们将参与研究,而人群是结果将应用的全部数据。在大多数情况下,对整个...

可能性(probability)和非概率抽样(non-probability sampling)的区别
...,在这种抽样技术中,群体中的被试有平等的机会被选为代表性样本。非概率抽样是一种抽样方法,其中不知道从总体中选择哪个个体作为样本。 交替称为随机抽样非随机抽样 选择依据随机任意地 选择的机会固定和已知...

了解分层样本及其制作方法
...最终样本中,而简单的随机抽样不能确保亚组在样本中的代表性相等或成比例。 比例分层随机抽样 在比例分层随机抽样中,当对整个人口进行检查时,每个阶层的规模与该阶层的人口规模成比例。这意味着每个地层具有相同...

社会学中不同类型的抽样设计
...此有时被称为方便样本,因为它不允许研究人员对样本的代表性进行任何控制。 虽然这种抽样方法有缺点,但如果研究人员想研究某个时间点在街角经过的人的特征,尤其是如果不可能进行这样的研究,这种方法是有用的。因...

社会学研究中的聚类样本
...一个主要缺点是,在所有类型的概率抽样中,它是最不具代表性的。一个群体中的个体通常具有相似的特征,因此,当研究人员使用整群抽样时,他或她有可能在某些特征方面具有代表性过高或代表性不足的群体。这可能会扭曲...

易于理解的(simple)和系统随机抽样(systematic random sampling)的区别
当我们形成一个统计样本时,我们在做什么时总是需要小心。可以使用多种不同的取样技术。其中一些比其他更合适。 通常,我们认为是一种样本,结果却是另一种样本。这可以在比较两种类型的随机样本时看到。简单随机...

什么是统计抽样?(statistical sampling?)
...要求他们阅读课本和小说。这是普通美国人的一个很差的代表性。一个好的样本将包含来自全国不同地区、各行各业、不同年龄段的人群。要获得这样一个样本,我们需要随机组合,这样每个美国人都有同等的概率参与样本。 ...
0 篇文章