为什么英语字符比其他字母表中的字符需要更少的字节来表示它们?
虽然我们大多数人可能从来没有停下来思考过这个问题,但字母字符在表示它们所需的字节数上并不完全相同。但为什么呢?今天的超级用户问答帖子回答了一位好奇的读者的问题。
今天的问答环节是由SuperUser提供的,SuperUser是Stack Exchange的一个分支,是一个由社区驱动的问答网站分组。
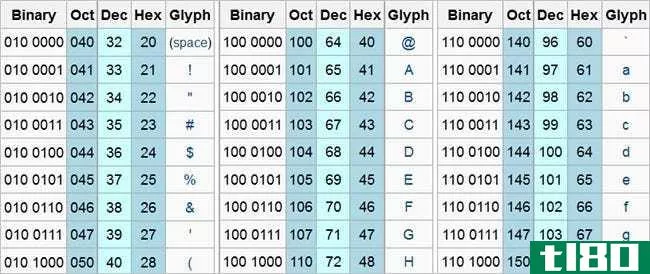
维基百科提供的部分ASCII图表截图。
问题
超级用户阅读器khajvah想知道为什么不同的字母表在保存时占用不同的磁盘空间:
When I put ‘a’ in a text file and save it, it makes it 2 bytes in size. But when I put a character like ‘ա’ (a letter from the Armenian alphabet) in, it makes it 3 bytes in size.
What is the difference between alphabets on a computer? Why does English take up less space when saved?
字母就是字母,对吧?也许不是!这个按字母顺序排列的谜的答案是什么?
答案
超级用户贡献者Doktoro Reichard和ernie为我们提供了答案。首先,Doktoro Reichard:
One of the first encoding schemes to be developed for use in mainstream computers is the ASCII (American Standard Code for Information Interchange) standard. It was developed in the 1960s in the United States.
The English alphabet uses part of the Latin alphabet (for instance, there are few accented words in English). There are 26 individual letters in that alphabet, not c***idering case. And there would also have to exist the individual numbers and punctuation marks in any scheme that pretends to encode the English alphabet.
The 1960s was also a time when computers did not have the amount of memory or disk space that we have now. ASCII was developed to be a standard representation of a functional alphabet across all American computers. At the time, the decision to make every ASCII character 8 bits (1 byte) long was made due to technical details of the time (the Wikipedia article menti*** the fact that perforated tape held 8 bits in a position at a time). In fact, the original ASCII scheme can be tran**itted using 7 bits, and the eighth could be used for parity checks. Later developments expanded the original ASCII scheme to include several accented, mathematical, and terminal characters.
With the recent increase of computer usage across the world, more and more people from different languages had access to a computer. That meant that, for each language, new encoding schemes had to be developed, independently from other schemes, which would conflict if read from different language terminals.
Unicode came into being as a solution to the existence of different terminals by merging all possible meaningful characters into a single abstract character set.
UTF-8 is one way to encode the Unicode character set. It is a variable-width encoding (i.e. different characters can have different sizes) and it was designed for backwards compatibility with the former ASCII scheme. As such, the ASCII character set will remain one byte in size whilst any other characters are two or more bytes in size. UTF-16 is another way to encode the Unicode character set. In comparison to UTF-8, characters are encoded as either a set of one or two 16-bit code units.
As stated in other comments, the ‘a’ character occupies a single byte while ‘ա’ occupies two bytes, denoting a UTF-8 encoding. The extra byte in the original question was due to the existence of a newline character at the end.
接下来是厄尼的回答:
1 byte is 8 bits, and can thus represent up to 256 (2^8) different values.
For languages that require more possibilities than this, a simple 1 to 1 mapping can not be maintained, so more data is needed to store a character.
Note that generally, most encodings use the first 7 bits (128 values) for ASCII characters. That leaves the 8th bit, or 128 more values for more characters. Add in accented characters, Asian languages, Cyrillic, etc. and you can easily see why 1 byte is not sufficient for holding all characters.
有什么要补充的解释吗?在评论中发出声音。想从其他精通技术的Stack Exchange用户那里了解更多答案吗?在这里查看完整的讨论主题。
- 发表于 2021-04-11 10:17
- 阅读 ( 228 )
- 分类:互联网
你可能感兴趣的文章
烧焦(char)和瓦查尔(varchar)的区别
...似的。在数据库设计中,使用了大量的数据类型。其中,字符数据类型得到了更突出的位置,因为与数字相比,字符数据类型用于存储大量信息。字符数据类型用于存储字符串中的字符或字母数字数据。数据库字符集的类型是在...

ascii和unicode文本之间有什么区别?
...别是,如果不通过替换重音字符(例如cafe)来将外来词英语化,就无法用ASCII表示café等其他语言的外来词。本地化的ASCII扩展是为了满足各种语言的需求而开发的,但是这些努力使得互操作性变得尴尬,并且明显地扩展了ASCII的...

电子邮件和表情符号:unicode如何帮助我们在线交流
... 要真正了解它们是什么,以及它们为什么对当今的通信如此重要,我们就必须跳进时光机回到19世纪。 ...

什么是ascii文本?它是如何使用的?
... ASCII是区分大小写的,这意味着它代表52个英文字母表中的大小写字母。除了相同的10位数字,这大约是所用空间的一半。 ...

如何在linux上使用fold命令
...输出。通过控制输出的宽度来读取大量文本、无穷无尽的字符串和未格式化的流。学习如何。 linux终端中文本行的工作原理 Linux战斗的第一条规则:了解你的敌人。让我们来定义它。一行文字到底是什么?它是由字母、数字、...

如何在linux中获得文件或目录的大小
...际磁盘使用情况以及文件或目录的真实大小。我们将解释为什么这些值不一样。 实际磁盘使用情况和实际大小 文件的大小和它在硬盘上占用的空间很少相同。磁盘空间按块分配。如果一个文件比一个块小,整个块仍然分配给...

如何在linux上使用strings命令
...。它的目的是什么?是否有指向列出二进制文件中可打印字符串的命令的点? 让我们后退一步。诸如程序文件之类的二进制文件可以包含人类可读文本的字符串。但是你怎么才能看到他们呢?如果你使用cat或更少,你很可能会...

如何在outlook中更改字符编码
...的网站中使用。UTF-8也是互联网邮件联盟推荐的编码。 我为什么要费心去换呢? Outlook与其他所有现代电子邮件客户端一样,对UTF-8进行编码和解码。 但是如果Outlook支持UTF-8,并且推荐使用UTF-8编码,为什么会看到不可读的字符...
什么是字符编码像ansi和unicode,他们有什么不同?
...符的拉丁字母表。它的7位编码只允许128个字符,这就是为什么世界各地都在使用一些非官方的变体。 ISO-8859–国际标准化组织最广泛使用的字符编码组是编号8859。每个特定的编码都由一个数字指定,通常以一个描述性名字作为...

烧焦(char)和瓦尔查尔(varchar)的区别
...库系统中,这两种类型都是数据类型,其中“char”表示字符,“varchar”表示变量字符。C中的Char表示用于存储字符串值的字符类型,主要是UTF-8编码的字符和整数。另一方面,Varchar是一种数据类型,它可以包含任何类型的长度...
0 篇文章





