如何阻止搜索引擎(block search engines)
方法1方法1/2:用机器人屏蔽搜索引擎。txt文件
- 1了解机器人。txt文件。一个机器人。txt文件是一个纯文本或ASCII文本文件,用于通知搜索引擎爬行器允许他们在您的网站上访问什么。列在列表中的文件和文件夹。txt文件可能不会被搜索引擎爬网和索引。你可能需要一个机器人。txt文件如果:你想阻止搜索引擎蜘蛛的特定内容。您正在开发一个实时网站,不准备让搜索引擎蜘蛛对您想要限制访问声誉良好的机器人的网站进行爬网和索引。
- 2创造、拯救和机器人。txt文件。要创建文件,请启动纯文本编辑器或代码编辑器。将文件另存为:robots。txt。文件名必须全部为小写。不要忘记“s”。保存文件时,请选择扩展名“'.txt”。如果使用Word,请选择“纯文本”选项。
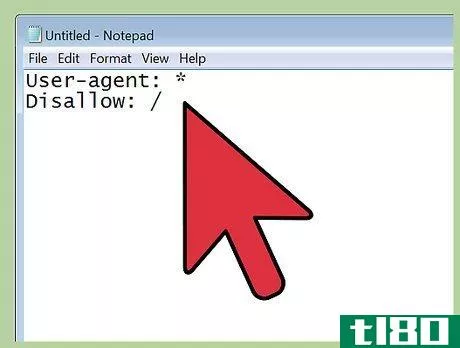
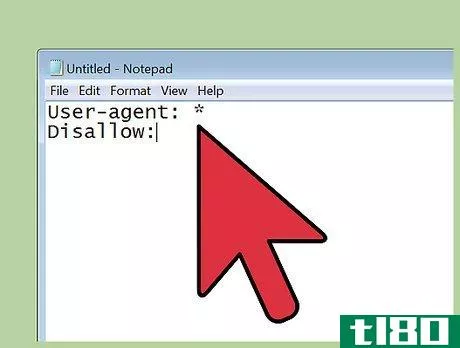
- 3.写一篇完全禁止机器人的文章。txt文件。它可以阻止每一个著名的搜索引擎蜘蛛爬行和索引您的网站与“完全不允许”的机器人。txt。在文本文件中写下以下几行:用户代理:*禁止:/n使用“完全禁止”选项。强烈建议不要使用txt文件。当Bingbot等机器人读取此文件时,它不会为您的网站编制索引,搜索引擎也不会显示您的网站。用户代理:这是搜索引擎蜘蛛或机器人的另一个术语*:星号表示代码适用于所有用户代理Disallow:/:正斜杠表示整个网站禁止机器人进入
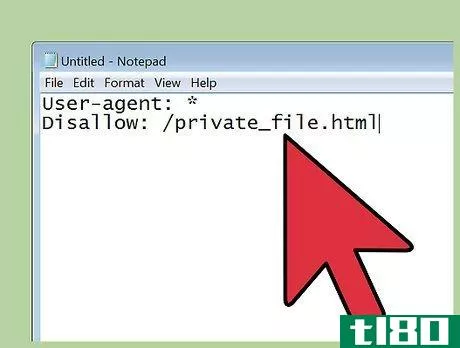
- 4编写一个允许机器人的条件语句。txt文件。与其拦截所有机器人,不如考虑拦截站点特定区域的特定蜘蛛。常见的条件允许命令包括:阻止特定机器人:将用户代理旁边的星号替换为googlebot、googlebot news、googlebot image、bingbot或teoma。阻止目录及其内容:用户代理:*不允许:/sample目录/阻止网页:用户代理:*不允许:/private_文件。htmlBlock an image:User agent:googlebot imageDisallow:/images\u mypicture。jpgBlock all images:User-agent:googlebot-imageDisallow:/Block特定文件格式:User-agent:*Disallow:/p*。gif$
- 5.鼓励机器人对你的网站进行索引和爬网。许多人希望欢迎而不是阻止搜索引擎蜘蛛,因为他们希望整个网站都被索引。要实现这一点,您有三个选择。首先,你可以选择不创建机器人。机器人找不到机器人时的txt文件。txt文件,它将继续抓取和索引您的整个网站。第二,你可以创建一个空的机器人。机器人将找到机器人。txt文件,识别它是空的,并继续抓取和索引您的网站。最后,你可以写一个完整的允许机器人。txt文件。使用代码:User agent:*不允许:当一个机器人(比如谷歌机器人)读取此文件时,它可以随意访问您的整个网站。用户代理:这是搜索引擎蜘蛛或机器人的另一个术语*:星号表示代码适用于所有用户代理disallow:空白disallow命令表示所有文件和文件夹都可以访问
- 6将txt文件保存到域的根目录下。在你写完机器人之后。txt文件,保存更改。将文件上载到站点的根目录。例如,如果你的域名是www.yourdomain。com,把机器人放好。www.yourdomain.txt文件。com/机器人。txt。
方法2方法2/2:用元标签屏蔽搜索引擎
- 1了解HTML机器人元标记。robots元标记允许程序员为机器人或搜索引擎爬行器设置参数。这些标签用于阻止机器人对整个网站或部分网站进行索引和爬行。您还可以使用这些标记阻止特定搜索引擎蜘蛛为您的内容编制索引。这些标记出现在HTML文件的头部。这种方法通常由无法访问网站根目录的程序员使用。
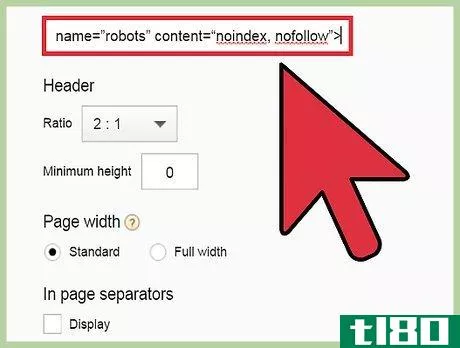
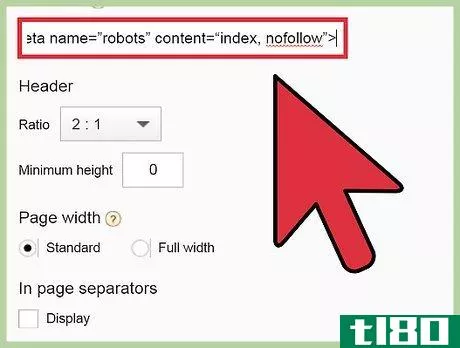
- 2从一个页面锁定机器人。可以阻止所有机器人为页面编制索引或跟踪页面链接。此标签通常在开发实时站点时使用。网站完成后,强烈建议您删除此标签。如果不删除标签,您的页面将无法通过搜索引擎进行索引或搜索。您可以阻止机器人为页面编制索引,并阻止其访问任何链接:<;meta name=“robots”content=“noindex,nofollow”>;您可以阻止所有机器人为页面编制索引:<;meta name=“robots”content=“noindex”>;您可以阻止所有机器人跟随页面链接:<;meta name=“robots”content=“nofollow”>;
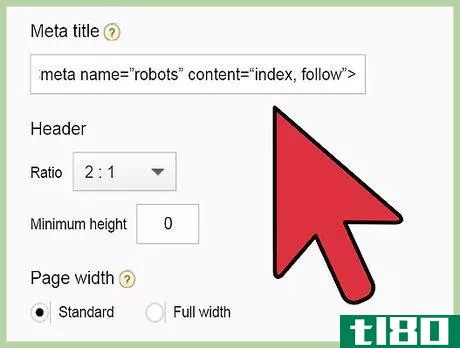
- 3允许机器人为页面编制索引,但不要跟随其链接。如果允许机器人为页面编制索引,页面将被编制索引;如果阻止爬行器跟随链接,则从该特定页面到其他页面的链接路径将中断。在标题中插入以下代码行:<;meta name=“robots”content=“index,nofollow”>;
- 4让搜索引擎蜘蛛跟随链接,但不要索引页面。如果你允许机器人跟随链接,从这个特定页面到其他页面的链接路径将保持不变;如果您限制他们为页面编制索引,您的网页将不会出现在索引中。在标题中插入以下代码行:<;meta name=“robots”content=“noindex,follow”>;
- 5锁定单个传出链接。要隐藏页面上的单个链接,请在<;a href></a>;链接标签。您可能希望使用此标记阻止指向要阻止的特定页面的其他页面上的链接&书信电报;a href=“yourdomain.html”rel=“nofollow”>;插入到被阻止页面的链接</a>;
- 6锁定特定的搜索引擎蜘蛛。与其阻止网页上的所有机器人,不如阻止一个机器人对网页进行爬行和索引。要实现这一点,请将meta标记中的“robot”替换为特定机器人的名称。例如:谷歌机器人、谷歌机器人新闻、谷歌机器人图片、宾宝机器人和特奥玛&书信电报;meta name=“bingbot”content=“noindex,nofollow”>;
- 7鼓励机器人抓取并索引你的页面。如果你想确保你的页面被编入索引并且其链接被跟踪,你可以在你的标题中插入一个follow-allow元“robot”标记。使用以下代码:<;meta name=“robots”content=“index,follow”>;



提示
- 发表于 2022-05-17 03:56
- 阅读 ( 39 )
- 分类:IT
你可能感兴趣的文章
如何从搜索引擎中删除你的facebook个人资料
Facebook允许像Google这样的搜索引擎索引你的个人资料和***息。但如果你不想让人们在Facebook之外查看你的社交资料,你可以选择将其从名单中删除。下面是方法。 首先,使用Windows10、Mac或Linux桌面浏览器访问Facebook网站,并登录...

搜索引擎(search engine)和浏览器(browser)的区别
搜索引擎与浏览器 关于两个最常用的流行词:搜索引擎和浏览器,有很多混淆。最近,谷歌在纽约街头进行了一次采访,要求人们定义浏览器。在一个超过50人的样本中,只有8%的人回答了浏览器的正确定义。 浏览器是本地安...

浏览器(browser)和搜索引擎(search engine)的区别
浏览器和搜索引擎的主要区别在于,浏览器是一种帮助访问和显示WWW网站的软件应用程序,而搜索引擎是一种帮助搜索WWW网站的软件应用程序。 浏览器和搜索引擎之间有着明显的区别,尽管有些人可以互换使用这两个词。搜索...

web浏览器(web browser)和搜索引擎(search engine)的区别
信不信由你,大多数人对网络浏览器和搜索引擎的区别几乎一无所知。如果你真的知道这两个词的区别,恭喜你,但是对于其他不知道的人,这里有一些提示可以很容易地区分这两个经常互换的词。 总结表格 web浏览器 搜索...

搜索引擎(search engine)和浏览器(browser)的区别
...相同。但是SEO更清楚同义词之间的区别以及原因。显然,搜索引擎和浏览器看起来像是同一个获取所需信息的工具。但事实是两者的目的不同,风格也不同。在走向不同之前,必须一个接一个地抓住两者的思想。 什么是搜索...

搜索引擎(search engine)和浏览器(browser)的区别
...常被使用,但人们并不知道它们的确切含义,例如网站、搜索引擎、浏览器等。搜索引擎(search engine) vs. 浏览器(browser)搜索引擎和浏览器的区别在于,搜索引擎允许用户在访问互联网后搜索互联网,而浏览器本身就是访问互联网...

将搜索引擎历史记录保密
随着最近AOL发布的搜索记录崩溃,重温EFF中的一些基本搜索引擎安全提示可能是个好主意:Don't put personally-identifying information in your searches, at least not in a way that can be associated with your other searches.Don't use a search engine operated by your ISP....

如何搜索引擎有效吗?(search engines work?)
搜索引擎基本上是计算机算法,帮助用户找到他们正在寻找的特定信息。不同的方法以不同的具体方式工作,但它们都使用相同的基本原则。 ...

什么是搜索引擎蜘蛛?(search engine spiders?)
搜索引擎爬行器是一种软件程序,可以对网页上的内容进行筛选,并建立出现在这些网页上的单词列表。这个过程称为网络爬网。该程序访问一页又一页,跟踪每个链接,...

什么是搜索引擎结果?(search engine results?)
搜索引擎结果是当一个人在搜索引擎上查找关键字或单词时出现的网站。启动搜索时出现的页面称为SERP或搜索引擎结果页面。实际上,一次搜索可以有多个SERP。 ...
0 篇文章





