标准偏差的范围规则
标准偏差和范围都是数据集扩展的度量。每个数字都以自己的方式告诉我们数据的间隔,因为它们都是变化的度量。虽然范围和标准偏差之间没有明确的关系,但有一条经验法则可以将这两个统计数据联系起来。这种关系有时被称为标准偏差的范围规则。

范围规则告诉我们,样本的标准偏差大约等于数据范围的四分之一。换句话说,s=(最大-最小)/4。这是一个非常简单的公式,只能作为标准偏差的粗略估计。
一个例子
要查看范围规则如何工作的示例,我们将查看以下示例。假设我们从数据值12、12、14、15、16、18、18、20、20、25开始。这些值的平均值为17,标准偏差约为4.1。相反,如果我们首先计算数据范围为25–12=13,然后将该数字除以4,则我们的标准偏差估计值为13/4=3.25。这个数字相对接近真实的标准偏差,适合粗略估计。
它为什么有效?
这个范围规则似乎有点奇怪。它为什么有效?把这个范围除以四不是完全任意的吗?我们为什么不用另一个数字除呢?事实上,在幕后进行着一些数学上的论证。
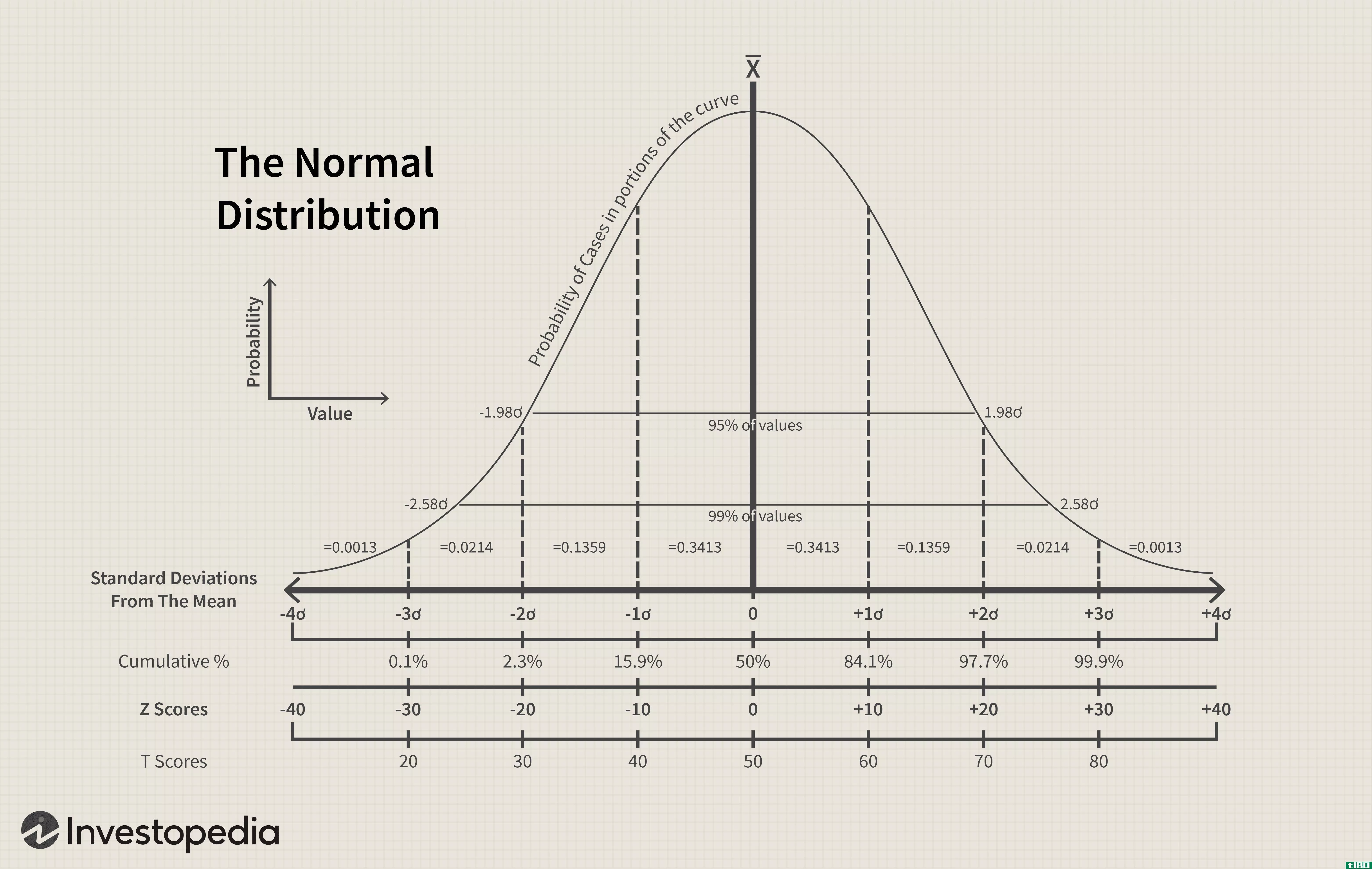
回想一下钟形曲线的性质和标准正态分布的概率。一个特征与在一定数量标准偏差范围内的数据量有关:
- 大约68%的数据在平均值的一个标准偏差范围内(较高或较低)。
- 大约95%的数据在平均值的两个标准偏差(较高或较低)范围内。
- 大约99%在平均值的三个标准偏差(较高或较低)范围内。
我们将使用的数字与95%有关。我们可以说,从低于平均值的两个标准偏差到高于平均值的两个标准偏差的95%,我们有95%的数据。因此,几乎所有的正态分布都会延伸到一个线段上,该线段总共有四个标准差长。
并非所有数据都是正态分布和钟形曲线。但大多数数据表现良好,偏离平均值两个标准差就可以捕获几乎所有的数据。我们估计并说四个标准偏差近似于范围的大小,因此范围除以四是标准偏差的粗略近似值。
用于范围规则
范围规则在许多设置中都很有用。首先,它是对标准偏差的快速估计。标准偏差要求我们首先找到平均值,然后从每个数据点减去该平均值,将差值平方,相加,除以数据点数量的1,然后(最后)取平方根。另一方面,范围规则只需要一次减法和一次除法。
范围规则有用的其他地方是当我们有不完整的信息时。像确定样本大小这样的公式需要三条信息:我们正在调查的总体的期望误差、置信水平和标准偏差。很多时候,不可能知道总体标准偏差是多少。通过范围规则,我们可以估计这个统计数据,然后知道我们应该制作多大的样本。
- 发表于 2021-09-12 04:24
- 阅读 ( 312 )
- 分类:数学
你可能感兴趣的文章

excel中标准差的计算
标准差是可以在Excel中计算出的众多统计数据之一。虽然这个过程很简单,但是在Excel中计算标准差对于初学者或者不熟悉microsoftexcel的人来说可能会很混乱。 ...
经验法则
...表明对于正态分布,几乎所有观察到的数据都将落在三个标准差内(表示为σ) 指平均数或平均数(用µ). 特别是,经验法则预测68%的观察值落在第一标准差之内(µ ± σ), 前两个标准差内95%(µ ± 2σ), 前三个标准差内99.7%(µ ± 三σ)...
使用正态分布优化你的投资组合
...险和尽可能高的回报。正态分布通过收益的均值和风险的标准差来量化这两个方面。 平均值或期望值 股票价格的平均日变化率可能为1.5%,也就是说,平均上涨1.5%。这个平均值或预期值表示回报,可以通过计算一个足够大的数...
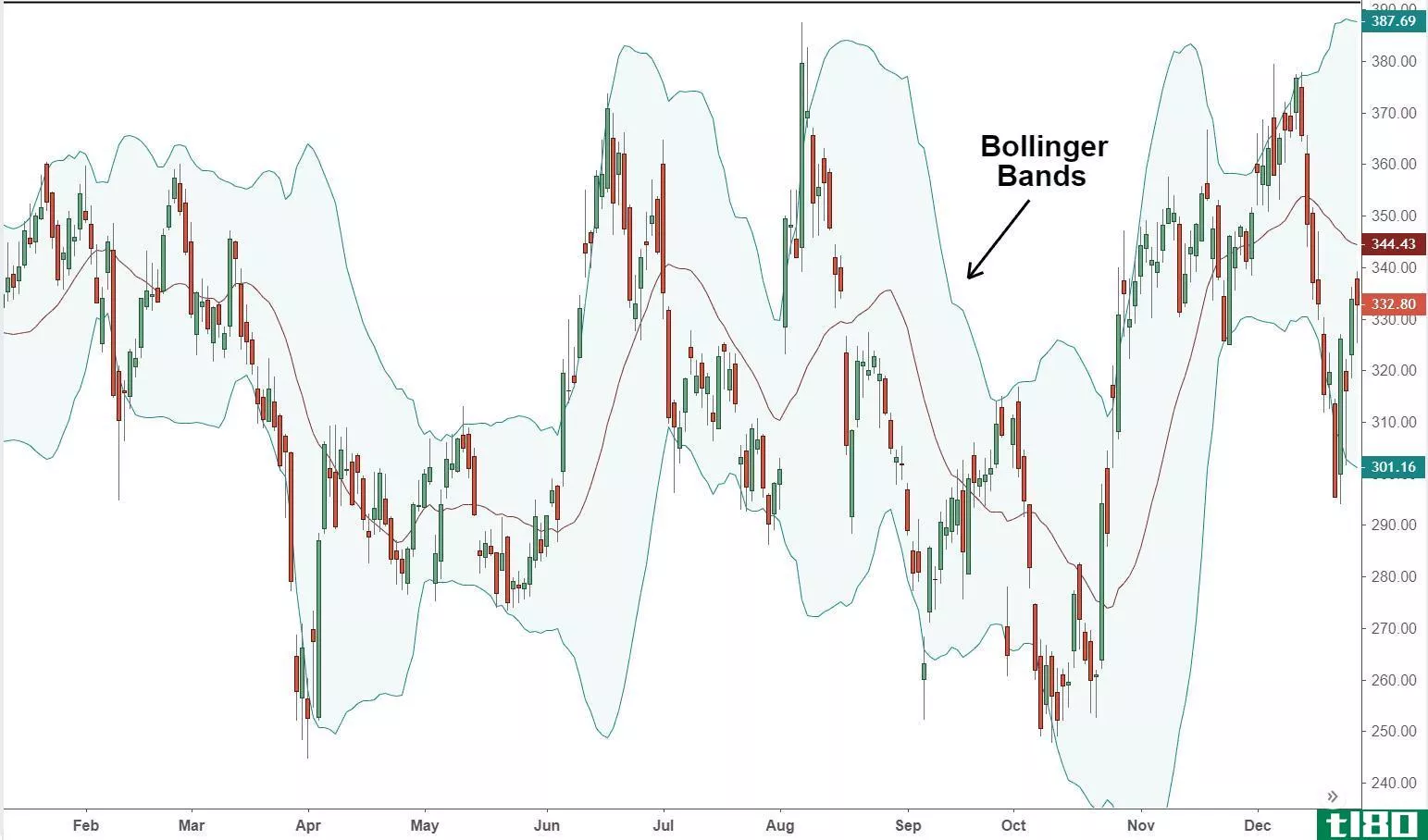
布林带® 定义
...些趋势线与证券价格的简单移动平均值(SMA)之间有两个标准差(正偏差和负偏差),但可以根据用户偏好进行调整。 布林线® 由著名技术交易员约翰·布林格开发并版权所有,旨在发现机会,使投资者更容易正确识别资产何...

标准差(standard deviation)和方差(variance)的区别
标准差和方差是数据离散度的统计度量数据也就是说,它们表示与平均值有多大的差异,或者值通常“偏离”平均值的程度平均值. 方差或标准差为零表示所有值都相同。方差是方差平方的平均值(即值与平均值的差值)...

β偏差(beta deviation)和标准差(standard deviation)的区别
...来衡量一只基金相对于其他基金的波动性。而另一方面,标准差也是一种统计工具,它也可以报告基金的波动性。β偏差(beta deviation) vs. 标准差(standard deviation)贝塔和标准差的区别在于,贝塔差衡量的是整个市场的风险,而标准...

分散(dispersion)和偏斜(skewness)的区别
...在于,离散度是计算数据不确定度或进行分析的一种度量标准,通过偏度来衡量介质中分布不平衡的程度。在数学分析和概率论中,它们是用来描述由大量计算数据组成的数据收集的最通用术语。色散是一个数学概念,它表示为...

标准偏差何时等于零?
样本标准差是一种描述性统计,用于测量定量数据集的传播。这个数字可以是任何非负实数。由于零是一个非负实数,因此值得一问,“样本标准偏差何时等于零?”这发生在非常特殊和非常不寻常的情况下,即我们所有的数...

什么是统计范围?(a range in statistics?)
...=99,其中添加一个额外的数据点极大地影响了范围的值。标准差是另一种不易受异常值影响的价差度量,但缺点是标准差的计算要复杂得多。 这个范围也没有告诉我们数据集的内部特征。例如,我们考虑数据集1, 1, 2、3, 4, 5、5...

置信区间在推断统计中的应用
...误差范围的形式如下: 误差幅度=(置信水平统计)*(标准差/误差) 置信水平的统计取决于使用的概率分布以及我们选择的置信水平。例如,如果我们的置信水平是正态分布,那么C是-z*到z*之间曲线下的面积。这个数字z*是...
0 篇文章





