高密度光纤(hdfs)和地图还原(mapreduce)的区别
HDFS和MapReduce的主要区别在于HDFS是一个分布式文件系统,提供对应用程序数据的高吞吐量访问,而MapReduce是一个软件框架,可以可靠地在大型集群上处理大数据。
大数据是一个大数据集的集合。它有三个主要特性:体积、速度和变化。Hadoop是一种允许存储和管理大数据的软件。它是一个用Java编写的开源框架。此外,它支持跨计算机集群的大型数据集的分布式处理。HDFS和MapReduce是Hadoop体系结构中的两个模块。
覆盖的关键领域
1.什么是HDFS–定义,功能2.什么是MapReduce–定义,功能3.HDFS和MapReduce之间的区别是什么–主要区别的比较
关键术语
大数据、HDFS、MapReduce

什么是高密度光纤(hdfs)?
HDFS代表Hadoop分布式文件系统。它是Hadoop的一个分布式文件系统,能够可靠、高效地运行在大型集群上。此外,它基于Google文件系统(GFS)。此外,它还有一个与文件系统交互的命令列表。
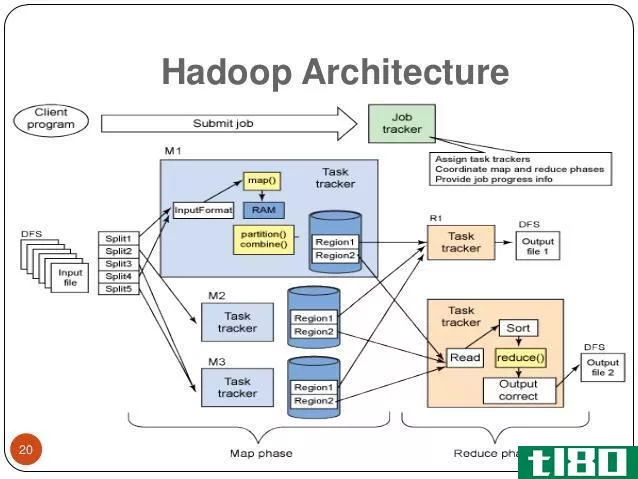
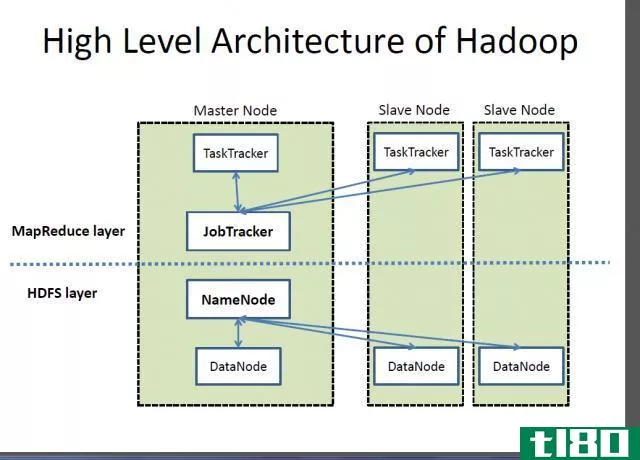
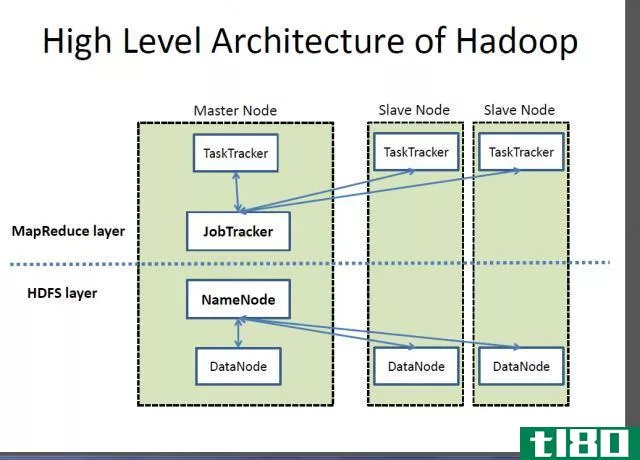
此外,HDFS按照主从结构工作。主节点或名称节点管理文件系统元数据,而从节点或数据注释存储实际数据。

Figure 1: HDFS Architecture
此外,HDFS名称空间中的一个文件被分割成几个块。数据节点存储这些块。并且,名称节点将块映射到数据节点,数据节点处理文件系统的读写操作。此外,它们按照名称节点的指示执行诸如块创建、删除等任务。
什么是地图还原(mapreduce)?
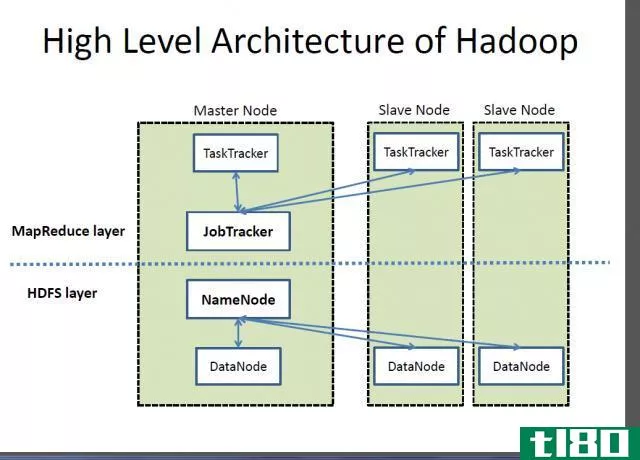
MapReduce是一个软件框架,允许编写应用程序在大型商用硬件集群上同时处理大数据。该框架由每个集群节点一个主任务跟踪器和一个从任务跟踪器组成。主机执行资源管理、在从机上调度作业、监视和重新执行失败的任务。另一方面,从任务跟踪器执行主任务所指示的任务,并不断地向主任务发回任务状态信息。

Figure 2: MapReduce Overview
另外,有两个任务与MapReduce相关。它们是map任务和reduce任务。map任务接收输入数据并将它们划分为键、值对的元组,而Reduce任务接收map任务的输出作为输入,并将这些数据元组连接成更小的元组。此外,map任务在reduce任务之前执行。
高密度光纤(hdfs)和地图还原(mapreduce)的区别
定义
HDFS是一种分布式文件系统,它在大型集群中跨多台计算机可靠地存储大型文件。相比之下,MapReduce是一个软件框架,可以轻松编写应用程序,以可靠、容错的方式在大型商用硬件集群上并行处理大量数据。这些定义解释了HDFS和MapReduce之间的主要区别。
主要功能
HDFS和MapReduce之间的另一个区别是HDFS提供了跨高度可伸缩Hadoop集群的高性能数据访问,而MapReduce执行大数据处理。
结论
简言之,HDFS和MapReduce是Hadoop体系结构中的两个模块。HDFS和MapReduce的主要区别在于HDFS是一个分布式文件系统,提供对应用程序数据的高吞吐量访问,而MapReduce是一个软件框架,可以可靠地在大型集群上处理大数据。
引用
1.“HDFS架构指南”,Apache Hadoop,可在此处获得。 2.“MapReduce教程”,ApacheHadoop,可在此处获得。3什么是Hadoop分布式文件系统(HDFS)?–来自WhatIs.com的定义。“SearchDataManagement,可在这里获得。 2.“MapReduce教程”,Apache Hadoop, 3.“什么是Hadoop分布式文件系统(HDFS)?–来自WhatIs.com的定义,“搜索数据管理,
- 发表于 2021-07-01 06:42
- 阅读 ( 148 )
- 分类:IT
你可能感兴趣的文章

胆固醇(cholesterol)和胆固醇酯(cholesteryl ester)的区别
...在细胞系统中同时起着结构和功能的作用。胆固醇也是高密度脂蛋白(HDL)和低密度脂蛋白(LDL)的重要组成部分。因此,它在心血管健康中起着重要作用。胆固醇和胆固醇酯是胆固醇存在于动物体内的两种形式。胆固醇是一种...
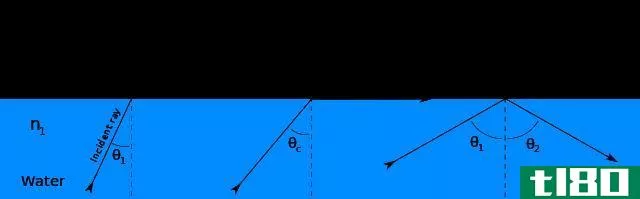
临界角(critical angle)和接受角(acceptance angle)的区别
...ical angle)? 临界角是一个入射角,超过这个角,光线通过密度较大的介质到达密度较小的介质表面时不再折射,而是完全反射。对于光纤,临界角是发生全内反射的最小入射角。 图01:防止光线反射回来的临界角 此外,如果光...
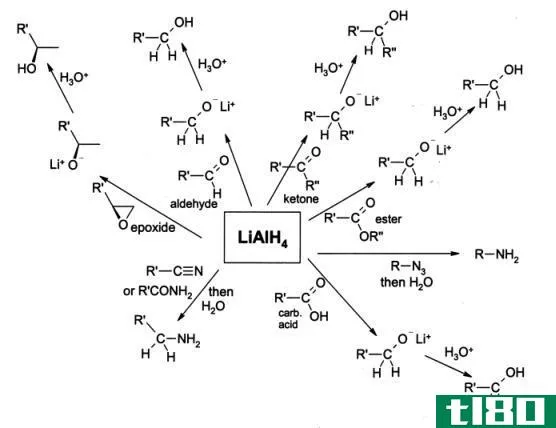
利亚尔4(lialh4)和nabh4(nabh4)的区别
...因是铝的电负性比硼低。因此,低电负性使Al-H中的电子密度比B-H键的电子密度向氢方向移动。因此,LiAlH4是一种较好的氢化物供体。 目录 1. 概述和主要区别 2. 什么是LiAlH4 3. 什么是NaBH4 4. 并列比较——LiAlH4与NaBH4表格形式 5. 摘...

谷歌将探索将光纤引入波特兰和亚特兰大等34个新城市
...面临的独特地方挑战,”谷歌说。这包括研究地形、房屋密度和当地基础设施。 潜在的城市也将参与进来,帮助推进这项工作,完成“一份项目清单,帮助他们为这样规模和速度的项目做好准备。” 谷歌说:...
hadoop软件(hadoop)和火花(spark)的区别
...计算性能的机制。Hadoop提供了一个计算框架,使用Google的MapReduce编程模型来存储和处理大数据。它可以与单个服务器一起工作,也可以扩展到包括数千台商品机器。尽管Hadoop是作为基于MapReduce范例的Apache软件基金会的一个开源项...
hadoop软件(hadoop)和数据库(mongodb)的区别
...个主要资源组成:Hadoop分布式文件系统(HDFS)、Google的MapReduce编程平台和整个Hadoop生态系统。Hadoop生态系统由一些模块组成,这些模块有助于对系统进行编程、管理和配置集群、管理和存储集群中的数据以及执行分析任务。hadoo...
数据库(hbase)和蜂巢(hive)的区别
...中存储的半结构化数据。这需要花费不必要的精力来编写MapReduce代码。虽然HBase和Hive都用作存储非结构化数据的数据存储,但它们是不同的。 什么是数据库(hbase)? HBase是一个开源的、非关系型的数据库管理系统,它的灵感...
hadoop软件(hadoop)和sql语句(sql)的区别
...常大的数据集;并提出了一种基于Java的分布式处理方法MapReduce。另一方面,SQLServer是关系数据库管理系统,是世界上众多商业和内部产品使用的最强大的数据平台之一,用于查询、操作和可视化各种数据源。 数据类型 –Hadoop设...
hadoop软件(hadoop)和卡桑德拉(cassandra)的区别
...作,使关系数据库的使用变得更加容易。Hadoop基于著名的MapReduce编程模型,适用于并行处理分布在节点集群上的巨大数据集。Hadoop分布式文件系统(HDFS)是Hadoop的数据存储和处理文件系统,运行在商用硬件上,提供对大量数据...
弹性搜索(elasticsearch)和hadoop软件(hadoop)的区别
...用于分析大量数据的工具和应用程序生态系统。Hadoop基于MapReduce编程模型,用于处理商品硬件集群上的巨大数据集。Hadoop的核心组件是Hadoop分布式文件系统(HDFS),它是一种高性能的并行文件系统,旨在满足大数据块流访问等...
0 篇文章