hadoop软件(hadoop)和火花(spark)的区别
大数据最大的问题之一是,大量的时间花在分析数据上,包括识别、清理和整合数据。数据的海量性和对数据分析的要求导致了数据科学的产生。但数据往往分散在许多业务应用程序和系统中,这使得它们有点难以分析。因此,需要对数据进行重新设计和重新格式化,以便于分析。这需要更复杂的解决方案,以使用户更容易访问信息。apachehadoop就是这样一种用于存储和处理大数据的解决方案,它与apachespark等许多其他大数据工具一起使用。但是哪一个是数据处理和分析的正确框架呢?Hadoop还是Spark?让我们看看。
apache hadoop
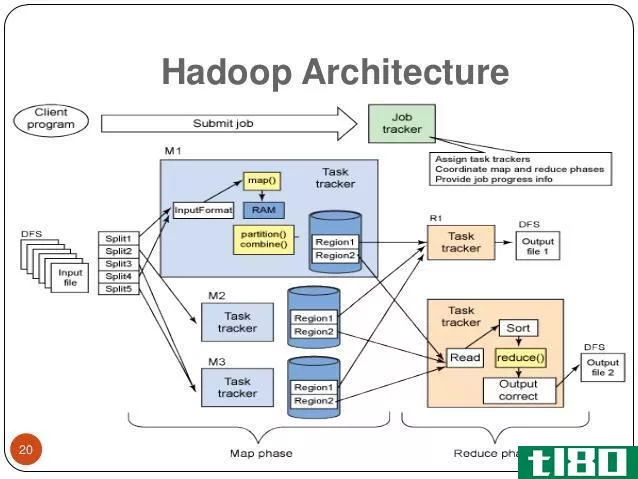
Hadoop是apachesoftwarefoundation的注册商标,是一个开放源码框架,用于跨计算机集群存储和处理非常大的数据集。它在合理的时间内以合理的成本处理非常大规模的数据。此外,它还提供了在规模上提高计算性能的机制。Hadoop提供了一个计算框架,使用Google的MapReduce编程模型来存储和处理大数据。它可以与单个服务器一起工作,也可以扩展到包括数千台商品机器。尽管Hadoop是作为基于MapReduce范例的Apache软件基金会的一个开源项目的一部分开发的,但是现在Hadoop有各种各样的发行版。然而,MapReduce仍然是一种用于聚合和计数的重要方法。MapReduce的基本思想是并行数据处理。
阿帕奇火花
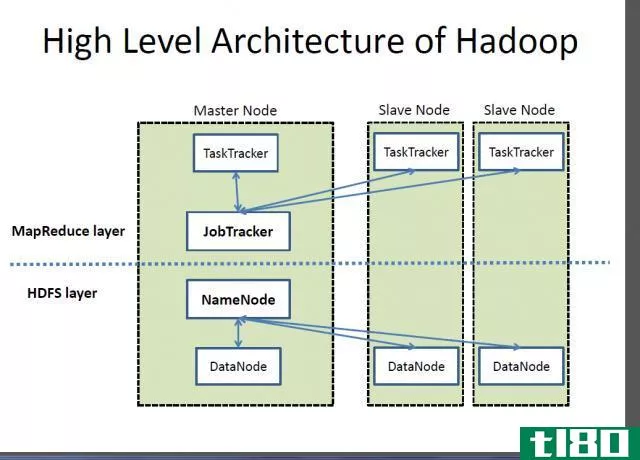
apachespark是一个开源的集群计算引擎和一组用于在计算机集群上进行大规模数据处理的库。Spark建立在hadoopmapreduce模型之上,是开发最为活跃的开源引擎,可以使数据分析更快,程序运行更快。它支持在apachehadoop平台上进行实时和高级分析。Spark的核心是一个由多个计算任务组成的调度、分发和监控应用程序组成的计算引擎。它的主要驱动目标是为编写大数据应用程序提供一个统一的平台。SCAP最初是在伯克利大学的APM实验室诞生的,现在它是Apache软件基金会的投资组合中的顶级开源项目之一。它无与伦比的内存计算能力使分析应用程序在apachespark上的运行速度比目前市场上的其他类似技术快100倍。
hadoop和spark的区别
框架
–Hadoop是Apache软件基金会的注册商标,是一个开放源码框架,用于跨计算机集群存储和处理非常大的数据集。基本上,它是一个数据处理引擎,可以在合理的时间内以合理的成本处理非常大规模的数据。apachespark是一个开源的集群计算引擎,构建在Hadoop的MapReduce模型之上,用于在计算机集群上进行大规模数据处理和分析。Spark支持在Apache Hadoop平台上进行实时和高级分析,以加快Hadoop计算过程。
演出
–Hadoop是用Java编写的,因此它需要编写长代码行,这需要更多的时间来执行程序。最初开发的hadoopmapreduce实现具有创新性,但也相当有限,而且不太灵活。另一方面,apachespark是用一种简洁、优雅的Scala语言编写的,以使程序运行更简单、更快。事实上,它运行应用程序的速度不仅比Hadoop快100倍,而且比市场上的其他类似技术也快100倍。
易用性
–Hadoop MapReduce范例具有创新性,但相当有限且缺乏灵活性。MapReduce程序是批量运行的,它们对于大规模的聚合和计数非常有用。另一方面,Spark提供了一致的、可组合的api,可用于从较小的片段或现有库构建应用程序。Spark的api也被设计成通过优化用户程序中组合在一起的不同库和函数来实现高性能。由于Spark将大部分输入数据缓存在内存中,这得益于RDD(弹性分布式数据集),它消除了多次加载到内存和磁盘存储的需要。
成本
–Hadoop文件系统(HDFS)是一种经济高效的方法,可以将大量结构化和非结构化数据存储在一个地方,以便进行深入分析。Hadoop的每TB成本远低于其他广泛用于维护企业数据仓库的数据管理技术的成本。另一方面,Spark在成本效率方面并不是一个更好的选择,因为它需要大量的RAM来缓存内存中的数据,这会增加集群,因此与Hadoop相比,成本会略微增加。
hadoop与spark:比较图

总结 - hadoop的(of hadoop) vs. 火花(spark)
Hadoop不仅是以经济高效的方式存储大量结构化和非结构化数据的理想选择,而且还提供了提高大规模计算性能的机制。尽管它最初是基于Google MapReduce模型开发的开源Apache软件基金会项目,但Hadoop现在有各种不同的发行版。ApacheSark构建在MapReduce模型之上,以提高效率,以使用更多类型的计算,包括流处理和交互查询。Spark支持在Apache Hadoop平台上进行实时和高级分析,以加快Hadoop计算过程。
- 发表于 2021-06-26 10:55
- 阅读 ( 265 )
- 分类:IT
你可能感兴趣的文章

关系数据库管理系统(rdbms)和hadoop公司(hadoop)的区别
RDBMS和Hadoop的关键区别在于RDBMS存储结构化数据,而Hadoop存储结构化、半结构化和非结构化数据。 关系数据库管理系统是一个基于关系模型的数据库管理系统。Hadoop是一种用于在商品硬件集群上存储数据和运行应用程序的软件...

大数据(big data)和hadoop公司(hadoop)的区别
关键区别——大数据与hadoop 数据在世界各地广泛收集。这种大量的数据称为大数据或大数据,常规存储设备无法处理。Hadoop软件框架是Apache软件基金会的一个开源框架,可以用来解决这个问题。大数据与Hadoop的关键区别在于...

5门课程对数据科学的温和介绍
...知识,然后再决定向大数据处理工具(如R编程、Python、Hadoop、Spar、Panda、Dremel等)迈进一步。 ...

铱(iridium)和铂火花塞(platinum spark plugs)的区别
铱与铂火花塞 除了常见的铜火花塞外,大多数用户还有两种选择;铂和铱插头。两种类型的火花塞都有相同的零件和结构,铱和铂火花塞的唯一区别是用于中心电极的金属。正如你可能已经发现的,铂塞使用铂,而铱塞使用铱...
hadoop软件(hadoop)和火花(spark)的区别
...需要更复杂的解决方案,以使用户更容易访问信息。apachehadoop就是这样一种用于存储和处理大数据的解决方案,它与apachespark等许多其他大数据工具一起使用。但是哪一个是数据处理和分析的正确框架呢?Hadoop还是Spark?让我们...
hadoop软件(hadoop)和数据库(mongodb)的区别
...据解决方案。在众多技术中,在存储和处理大数据方面,Hadoop和MongoDB是两种流行的选择。虽然两者在基本上是相似的,但他们的方法是非常不同的。让我们看看。 什么是数据库(mongodb)? MongoDB是一个开源文档数据库,它已经...
数据库(hbase)和蜂巢(hive)的区别
HBase和Hive都是基于Hadoop的数据仓库结构,在存储和查询数据的方式上有很大的不同。通过传统的数据库管理工具来管理和处理大量基于web的数据变得越来越困难。这就是HBase的用武之地。HBase是处理大量数据的首选。例如,如果...
hadoop软件(hadoop)和sql语句(sql)的区别
...设备的数量不断增加,数据量激增。大数据正是开源框架Hadoop的用武之地。Hadoop提供了一个用于存储和检索大量数据以进行处理和分析的框架。但是Hadoop与其他数据库管理系统(如sqlserver)有什么不同呢?我们将重点介绍SQL和Had...
hadoop软件(hadoop)和卡桑德拉(cassandra)的区别
...的海量数据,存储和分析这些海量数据的能力已经提高。Hadoop是设计用来处理如此大量数据(通常称为大数据)的复杂工具之一。Cassandra是另一个易于部署和管理的高度可扩展数据库。但Hadoop和Cassandra哪个是最好的选择? 什...
弹性搜索(elasticsearch)和hadoop软件(hadoop)的区别
...搜索引擎,Elasticsearch是一个分布式的多租户文档存储。Hadoop是一个分布式框架,它允许使用简单的编程模型在分布式环境中跨计算机集群存储和处理大数据。 什么是弹性搜索(elasticsearch)? Elasticsearch是一个高度可扩展的分布...
0 篇文章