KDD与数据挖掘
KDD(knowledgediscoveryingindatabases)是计算机科学的一个领域,它包括帮助人类从大量的数字化数据中提取有用的和以前未知的信息(即知识)的工具和理论。KDD包括几个步骤,数据挖掘就是其中之一。数据挖掘是应用特定的算法从数据中提取模式。尽管如此,KDD和数据挖掘是可以互换使用的。
什么是KDD?
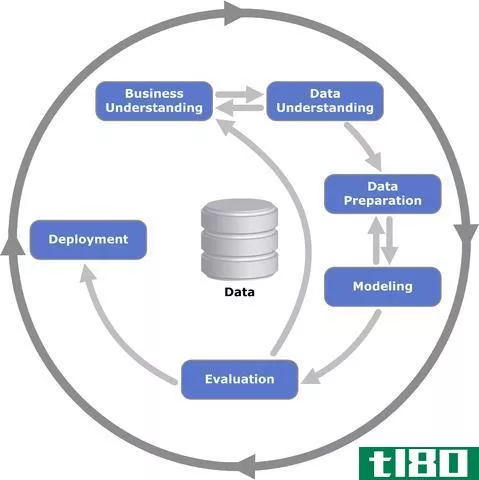
如上所述,KDD是计算机科学的一个领域,它处理从原始数据中提取先前未知和有趣的信息。KDD是通过开发适当的方法或技术来尝试理解数据的整个过程。这个过程处理的是将低级数据映射到其他更紧凑、抽象和有用的形式。这是通过创建短报告、对生成数据的过程进行建模以及开发可以预测未来病例的预测模型来实现的。由于数据的指数级增长,特别是在商业等领域,KDD已经成为将大量数据转化为商业智能的一个非常重要的过程,因为在过去几十年中,人工提取模式似乎变得不可能。例如,它目前被用于各种应用,如社会网络分析、欺诈检测、科学、投资、**、电信、数据清理、体育、信息检索等,而且主要用于市场营销。KDD通常用来回答这样的问题:哪些主要产品可能有助于明年在沃尔玛获得高利润?。这个过程有几个步骤。它从了解应用程序域和目标开始,然后创建目标数据集。接下来是数据的清理、预处理、缩减和投影。下一步是使用数据挖掘(下面解释)来识别模式。最后,发现的知识通过可视化和/或解释来巩固。
什么是数据挖掘?
如上所述,数据挖掘只是整个KDD过程中的一个步骤。应用程序的目标定义了两个主要的数据挖掘目标,即验证或发现。验证是验证用户对数据的假设,而发现是自动发现有趣的模式。有四个主要的数据挖掘任务:聚类、分类、回归和关联(摘要)。聚类是从非结构化数据中识别相似的组。分类是学习可以应用于新数据的规则。回归是寻找对数据建模误差最小的函数。关联是寻找变量之间的关系。然后,需要选择具体的数据挖掘算法。根据目标,可以选择线性回归、logistic回归、决策树和朴素贝叶斯等不同的算法。然后在一个或多个表示形式中搜索感兴趣的模式。最后,使用预测精度或可理解性对模型进行评估。
KDD和数据挖掘有什么区别?