hadoop软件(hadoop)和火花(spark)的区别
Hadoop和Spark的主要区别在于Hadoop是一个Apache开源框架,它允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理,而Spark是一个为快速Hadoop计算而设计的集群计算框架。
大数据是指数据量大、速度快、种类多的集合。因此,不可能使用传统的数据存储和处理方法来分析大数据。Hadoop是一种高效存储和处理大数据的软件。但另一方面,Spark是一个Apache框架,用于提高Hadoop的计算速度。它可以处理批处理和实时分析以及数据处理工作负载。
覆盖的关键领域
1.什么是Hadoop–定义,功能2.什么是Spark–定义,功能3.Hadoop和Spark之间的区别是什么–主要区别的比较
关键术语
大数据、Hadoop、Spark

什么是hadoop软件(hadoop)?
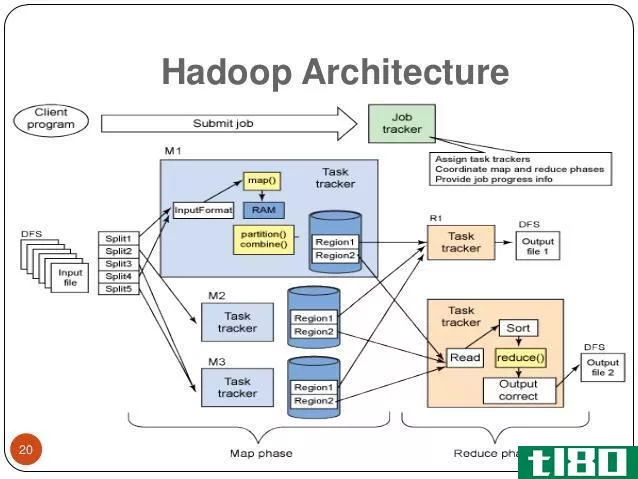
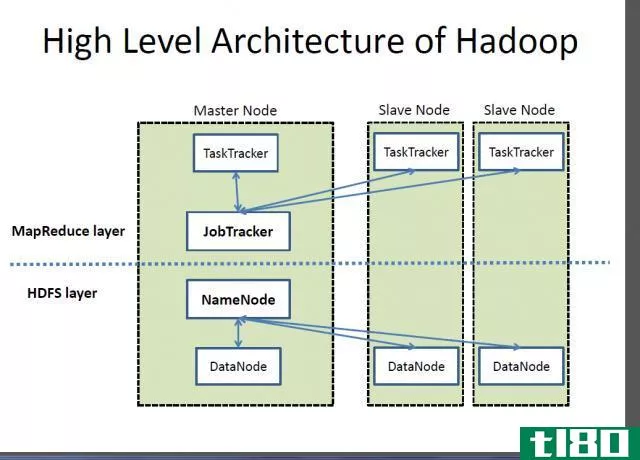
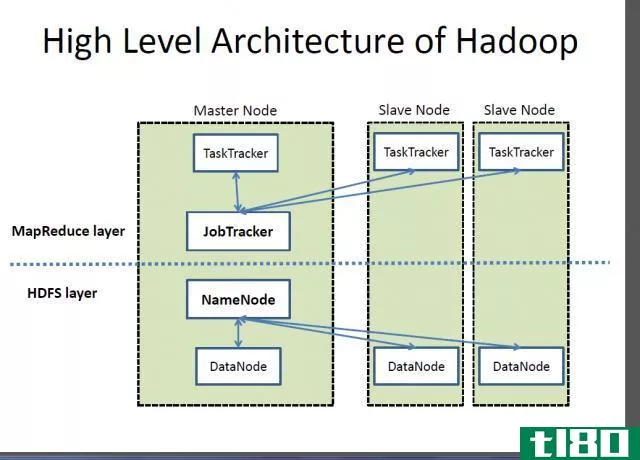
Hadoop是由Apache软件基金会开发的开源框架。它用于在分布式环境中存储大数据,以便同时处理它们。此外,它还跨计算机集群提供分布式存储和计算。此外,Hadoop体系结构中有四个主要组件。他们是;Hadoop文件分布式系统(HDFS)、hadoopmapreduce、hadoopcommon和hadoopyarn。

HDFS是Hadoop存储系统。它按照主从结构工作。主节点管理文件系统元数据。其他计算机作为从属节点或数据节点工作。此外,数据在这些数据节点之间被划分。同样,hadoopmapreduce包含处理数据的算法。这里,主节点在从节点上运行map reduce作业。并且,从属节点完成任务并将结果发送回主节点。此外,hadoopcommon还提供了Java库和实用程序来支持其他组件。另一方面,Hadoop纱线执行集群资源管理和作业调度。
什么是火花(spark)?
Spark是提高Hadoop计算速度的Apache框架。它有助于Hadoop减少查询之间的等待时间,并最小化运行程序的等待时间。

Spark-SQL、Spark-Streaming、MLib、GraphX和apachespark-Core是Spark的主要组件。
Spark Core–所有功能都建立在Spark Core之上。它是spark平台的通用执行引擎。它在外部存储系统中提供内存计算和引用数据集。
sparksql–提供支持结构化和半结构化数据的SchemaRDD。
Spark Streaming–提供执行流分析的功能。
MLib–一个分布式机器学习框架。sparkmlib比基于Hadoop磁盘的apachemahout版本更快。
GraphX–一个分布式图形处理框架。它提供了一个表示图计算的API,可以使用Pregel抽象API对用户定义的图进行建模。
hadoop软件(hadoop)和火花(spark)的区别
定义
Hadoop是一个Apache开源框架,它允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。apachespark是一个开源的分布式通用集群计算框架。因此,这就解释了Hadoop和Spark之间的主要区别。
速度
速度是Hadoop和Spark的另一个区别。Spark比Hadoop执行得更快。
容错
Hadoop使用在多个副本中复制数据来实现容错。Spark使用弹性分布式数据集(RDD)进行容错。
应用程序编程接口
Hadoop和Spark的另一个区别是Spark提供了多种api,可以用于多种数据源和语言。而且,它们比hadoopapi更具可扩展性。
使用
Hadoop用于管理在集群系统中运行的大数据应用程序的数据存储和处理。Spark用于促进Hadoop计算过程。因此,这也是Hadoop和Spark之间的一个重要区别。
结论
总之,Hadoop和Spark的区别在于Hadoop是一个Apache开源框架,它允许使用简单的编程模型跨计算机集群分布式处理大型数据集,而Spark是一个集群计算框架,专为快速Hadoop计算而设计。两者都可以用于基于预测分析、数据挖掘、机器学习等的应用。
引用
1.“Hadoop–Hadoop简介”。Www.tutorialspoint.com,Tutorials Point,此处提供。2Apache Spark简介。“Www.tutorialspoint.com,Tutorials Point,可在此处获得。 2.“Apache Spark简介”,Www.tutorialspoint.com,Tutorials Point,
- 发表于 2021-07-01 02:58
- 阅读 ( 232 )
- 分类:IT
你可能感兴趣的文章

关系数据库管理系统(rdbms)和hadoop公司(hadoop)的区别
RDBMS和Hadoop的关键区别在于RDBMS存储结构化数据,而Hadoop存储结构化、半结构化和非结构化数据。 关系数据库管理系统是一个基于关系模型的数据库管理系统。Hadoop是一种用于在商品硬件集群上存储数据和运行应用程序的软件...

大数据(big data)和hadoop公司(hadoop)的区别
关键区别——大数据与hadoop 数据在世界各地广泛收集。这种大量的数据称为大数据或大数据,常规存储设备无法处理。Hadoop软件框架是Apache软件基金会的一个开源框架,可以用来解决这个问题。大数据与Hadoop的关键区别在于...

5门课程对数据科学的温和介绍
...知识,然后再决定向大数据处理工具(如R编程、Python、Hadoop、Spar、Panda、Dremel等)迈进一步。 ...

铱(iridium)和铂火花塞(platinum spark plugs)的区别
铱与铂火花塞 除了常见的铜火花塞外,大多数用户还有两种选择;铂和铱插头。两种类型的火花塞都有相同的零件和结构,铱和铂火花塞的唯一区别是用于中心电极的金属。正如你可能已经发现的,铂塞使用铂,而铱塞使用铱...
hadoop软件(hadoop)和火花(spark)的区别
...需要更复杂的解决方案,以使用户更容易访问信息。apachehadoop就是这样一种用于存储和处理大数据的解决方案,它与apachespark等许多其他大数据工具一起使用。但是哪一个是数据处理和分析的正确框架呢?Hadoop还是Spark?让我们...
hadoop软件(hadoop)和数据库(mongodb)的区别
...据解决方案。在众多技术中,在存储和处理大数据方面,Hadoop和MongoDB是两种流行的选择。虽然两者在基本上是相似的,但他们的方法是非常不同的。让我们看看。 什么是数据库(mongodb)? MongoDB是一个开源文档数据库,它已经...
数据库(hbase)和蜂巢(hive)的区别
HBase和Hive都是基于Hadoop的数据仓库结构,在存储和查询数据的方式上有很大的不同。通过传统的数据库管理工具来管理和处理大量基于web的数据变得越来越困难。这就是HBase的用武之地。HBase是处理大量数据的首选。例如,如果...
hadoop软件(hadoop)和sql语句(sql)的区别
...设备的数量不断增加,数据量激增。大数据正是开源框架Hadoop的用武之地。Hadoop提供了一个用于存储和检索大量数据以进行处理和分析的框架。但是Hadoop与其他数据库管理系统(如sqlserver)有什么不同呢?我们将重点介绍SQL和Had...
hadoop软件(hadoop)和卡桑德拉(cassandra)的区别
...的海量数据,存储和分析这些海量数据的能力已经提高。Hadoop是设计用来处理如此大量数据(通常称为大数据)的复杂工具之一。Cassandra是另一个易于部署和管理的高度可扩展数据库。但Hadoop和Cassandra哪个是最好的选择? 什...
弹性搜索(elasticsearch)和hadoop软件(hadoop)的区别
...搜索引擎,Elasticsearch是一个分布式的多租户文档存储。Hadoop是一个分布式框架,它允许使用简单的编程模型在分布式环境中跨计算机集群存储和处理大数据。 什么是弹性搜索(elasticsearch)? Elasticsearch是一个高度可扩展的分布...
0 篇文章