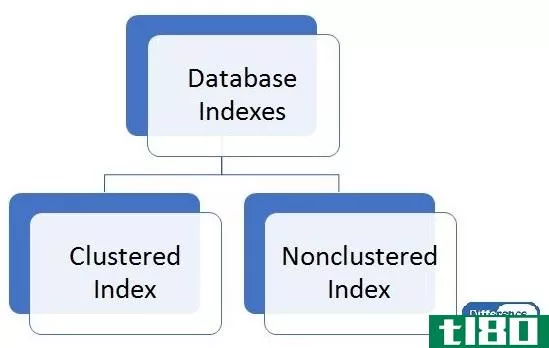
群集的(clustered)和非聚集索引(nonclustered index)的区别
**索引和非**索引的主要区别在于,每个表只有一个**索引,而每个表有多个非**索引。
首先,索引是一种从数据库文件中轻松高效地检索记录的技术。它加快了使用数据库的客户机应用程序的查询性能。此外,索引有两种类型:**索引和非**索引。**索引更改数据在磁盘中的存储顺序。但是,在非**索引中,索引的逻辑顺序与磁盘中存储的数据的物理顺序不匹配。
覆盖的关键领域
1.什么是索引–定义,功能2.什么是**索引–定义,功能3.什么是非**索引–定义,功能4.**索引和非**索引的区别是什么–关键区别的比较
关键术语
**索引

什么是索引(an index)?
假设一个表存储客户的详细信息。它有三列作为名字,姓氏和联系电话。如果表中没有索引,则数据将不按任何特定顺序**存储器中的可用空间。如果用户需要获取特定客户的电话号码,则需要从头开始搜索数据。即使我们得到了数据,也有必要继续到最后,因为最后可能会有匹配的数据。索引在这些情况下很有用。
什么是**索引(a clustered index)?
**索引更改数据的物理存储顺序。表数据按物理顺序排列后,DBMS将创建索引页。它们有助于轻松导航到所需的数据。包含基表数据的整个结构称为**索引。通过**索引树导航到基表数据的查询过程称为**索引查找。每个表有一个**索引,因为如果不使用单独的结构,就不可能以两种不同的方式物理地排列数据。
什么是非**索引(a nonclustered index)?
非**索引不会对表中的物理数据进行排序。索引和表存储在不同的位置。此外,还有指向表中数据的指针或引用。可以按任何顺序存储数据,因为该顺序独立于基表数据。因此,每个表可以有多个非**索引。基表中的数据在堆中,而引用是行标识符。

对列执行查询时,数据库首先转到索引并查找表中相应行的地址。然后,它转到行地址并获取其他列值。因此,非**索引比**索引慢。当表中定义了唯一键时,将自动创建非**索引。
群集的(clustered)和非**索引(nonclustered index)的区别
定义
**索引是一种索引类型,其中表记录被物理地重新排序以匹配索引。另一方面,非**索引是一种特殊类型的索引,其中索引的逻辑顺序与磁盘上行的物理存储顺序不匹配。这些定义解释了**索引和非**索引之间的区别。
索引数
每个表的索引数是**索引和非**索引的主要区别。一个表可以有一个**索引,但可以有多个非**索引。
功能
**索引不存储指向实际数据的指针。但是,非**索引同时存储值和指向保存数据的实际行的指针。因此,这是**索引和非**索引之间的另一个区别。
数据存储顺序
此外,群集索引决定了在磁盘上存储数据的顺序,而非群集索引对在磁盘上存储数据的顺序没有影响。
所需内存空间
此外,非**索引比**索引需要更多的内存空间。
速度
速度是**索引和非**索引的另一个区别。非**索引比**索引慢。
结论
索引有两种类型:**索引和非**索引。**索引和非**索引的区别在于,每个表只有一个**索引,而每个表有多个非**索引。简言之,非**索引比**索引速度慢,需要更多的空间。
引用
1.亚达夫,杜尔加普**德。”Sql Server中的索引。“LinkedIn幻灯片,2015年11月21日,此处提供。2。拉哈曼,马哈布伯。”《Sql Server索引简介》,LinkedIn幻灯片,2015年5月23日,点击此处。 2.拉哈曼,马哈布伯。”介绍Sql Server索引。”LinkedIn幻灯片,2015年5月23日,
- 发表于 2021-07-01 06:10
- 阅读 ( 216 )
- 分类:IT
你可能感兴趣的文章
丛生的(clustered)和非聚集索引(nonclustered index)的区别
...同,所以数据访问是系统的、快速的。 什么是非**指数(nonclustured index)? 在非**索引中,索引指向实际数据。非**索引是对数据的引用。因此,每个表可以有多个索引。非**索引的一个例子是一本书,它包含了带有标题和相应页码...
聚类(clustering)和分类(classification)的区别
... 4. 并列比较-聚类与表格形式的分类 5.摘要 什么是聚类(clustering)? 聚类是一种对对象进行分组的方法,使具有相似特征的对象**在一起,而具有不同特征的对象分开。它是机器学习和数据挖掘中常用的统计数据分析技术。探索性...
为什么谷歌搜索结果比本地硬盘查询快?
...非常慢。 答案 超级用户贡献者Simon强调了Google搜索查询和非索引Windows搜索之间的根本区别: Google is not searching the internet: it is searching an index. Google has huge server farms which are c***tantly scanning and indexing the internet. This process takes a lot of...

指数(index)和目录(contents)的区别
...开头。 书籍类型 索引通常出现在非小说类书籍中。 小说和非小说都有内容。 信息 索引列出了不同的主题和关键字。 目录列出章节和分章。 秩序 索引按顺序列出。 内容按字母顺序排列。 长度 索引通常比内容长。 内容节比索...

集群(cluster)和网格计算(grid computing)的区别
...别比较 关键术语 集群计算、网格计算 什么是集群计算(cluster computing)? 在集群计算中,两台或多台计算机协同工作来解决一个问题。群集设备通过快速局域网(LAN)连接。群集中的每个设备称为节点。每个节点都有相同的硬件...

索引(indexing)和散列(hashing)的区别
索引和散列的主要区别在于,索引通过减少处理查询的磁盘访问次数来优化数据库的性能,而散列则在不使用索引结构的情况下计算数据记录在磁盘上的直接位置。 数据库是相关数据的集合。DBMS或数据库管理系统允许轻松地创...

主要的,重要的(primary)和二级索引(secondary index)的区别
主索引和次索引之间的主要区别在于,主索引是包含主键且不包含重复项的一组字段上的索引,而次索引是不是主索引且可以包含重复项的索引。 索引是一个帮助优化数据库性能的过程。它减少了处理查询的磁盘访问次数。索...

目录(table of contents)和指数(index)的区别
...帮助读者轻松地找到想要搜索的内容,这就需要内容表和索引。“不要以封面来判断一本书”,他们说,这是恰当的。一个人可以根据它所涵盖的内容来判断一本书,所涵盖的章节可以很容易地通过一页内容或一个索引来分析。...

如何在css中使用z索引(use z-index in css)
...的位置。在这两个示例中,基本上都是设置这些对象的z索引。 什么是z指数(z-index)? 当您使用CSS定位来定位页面上的元素时,您需要从三维角度进行思考。有两个标准尺寸:左/右和上/下。从左到右的索引称为x索引,而从上...

聚类分析及其在科研中的应用
...据中的结构而不解释它们存在的原因。 什么是群集(clustering)? 聚类几乎存在于我们日常生活的每个方面。以杂货店的物品为例。不同类型的物品总是显示在相同或附近的位置——肉类、蔬菜、苏打水、谷类食品、纸制品等...
0 篇文章





