什么是刮网?如何从网站收集数据
Web scraper自动收集通常只能通过浏览器访问网站才能访问的信息和数据。通过自主地这样做,web抓取脚本在数据挖掘、数据分析、统计分析等方面打开了一个可能性的世界。

为什么刮网有用
我们生活在一个比任何时候都更容易获得信息的时代。用来传递你正在阅读的这些单词的基础设施是一个通往更多知识、观点和新闻的渠道,这是人类历史上人们从未接触过的。
事实上,即使最聪明的人的大脑被提高到100%的效率(应该有人为此**一部电影),光是在美国,仍然无法容纳互联网上存储的1/1000的数据。
Cisco在2016年估计,互联网流量超过了1个zettabyte,即1000000000000000000字节,或者1个sextillion字节(继续,对着sextillion傻笑)。一个zettabyte是流媒体Netflix的四千年历史。这就相当于,如果你,勇敢的读者,从头到尾不停地浏览办公室50万次。

所有这些数据和信息都非常吓人。不是所有的都是对的。这些信息与日常生活的关系不大,但越来越多的设备将这些信息从世界各地的服务器传送到我们的眼睛和大脑。
由于我们的眼睛和大脑不能真正处理所有这些信息,网络抓取已经成为一种有用的方法,通过编程从互联网收集数据。Web抓取是一个抽象的术语,它定义了从网站中提取数据以将其保存在本地的行为。
想想一种类型的数据,你也许可以通过抓取网页来收集它。房地产清单、体育数据、你所在地区企业的电子邮件地址,甚至你最喜欢的艺术家的歌词,都可以通过编写一个小脚本来查找和保存。
浏览器如何获取web数据?
要理解web scraper,我们首先需要了解web是如何工作的。要访问此网站,请键入“makeuseof.com网站“或者您单击了另一个网页的链接(告诉我们在哪里,说真的,我们想知道)。不管怎样,接下来的几个步骤都是一样的。
首先,你的浏览器将获取你输入或点击的网址(专业提示:在点击之前,将鼠标悬停在链接上方,查看浏览器底部的网址,以避免受到朋克攻击),并形成一个“请求”发送到服务器。然后服务器将处理请求并发送响应。
服务器的响应包含HTML、JavaScript、CSS、JSON和其他数据,这些数据允许您的web浏览器形成一个供您查看的网页。
检查web元素
现代浏览器允许我们了解这个过程的一些细节。在Windows上的googlechrome中,您可以按Ctrl+Shift+I或右键单击并选择Inspect。窗口将显示如下屏幕。
选项的选项卡列表列在窗口的顶部。现在感兴趣的是网络标签。这将提供有关HTTP流量的详细信息,如下所示。
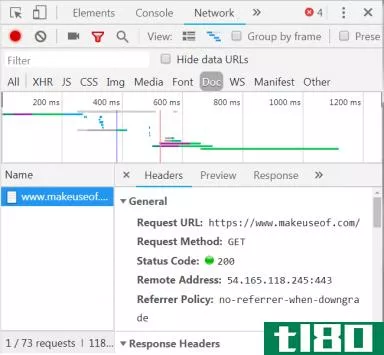
在右下角,我们看到了有关HTTP请求的信息。URL是我们所期望的,而“method”是一个HTTP“GET”请求。响应中的状态代码列为200,这意味着服务器认为请求有效。
在状态码下面是远程地址,这是服务器的面向公众的IP地址makeuseof.com网站服务器。客户端通过DNS协议获得这个地址。
下一节将列出有关响应的详细信息。响应头不仅包含状态代码,还包含响应包含的数据或内容的类型。在本例中,我们将使用标准编码查看“text/html”。这告诉我们,响应实际上是呈现网站的HTML代码。
其他类型的响应
此外,服务器可以返回数据对象作为对GET请求的响应,而不是只返回HTML供web页面呈现。网站的应用程序编程接口(或API)通常使用这种类型的交换。
仔细阅读如上所示的Network选项卡,您可以看到是否存在这种类型的交换。调查CrossFit开放式排行榜时,会显示用数据填充表格的请求。
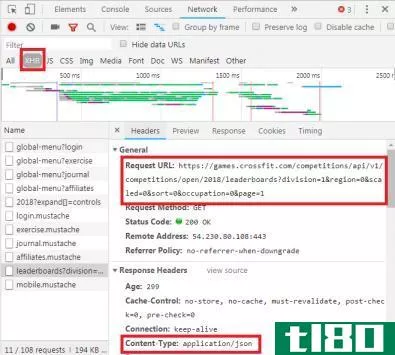
通过单击响应,将显示JSON数据,而不是呈现网站的HTML代码。JSON中的数据是一系列标签和值,它们位于一个分层的、轮廓分明的列表中。
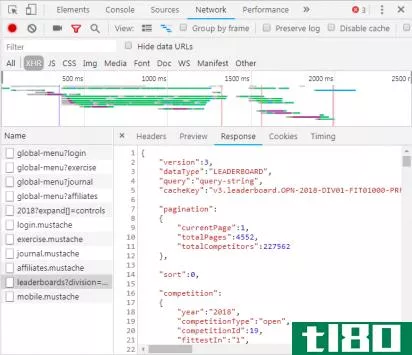
手动解析HTML代码或遍历数以千计的JSON键/值对非常类似于读取矩阵。乍一看,这看起来像胡言乱语。信息可能太多,无法手动解码。
网络搜寻者来营救!
现在,在你要求蓝色药丸离开这里之前,你应该知道我们不必手动解码HTML代码!无知不是幸福,这牛排很好吃。
网络刮板可以为您执行这些困难的任务。抓取框架有Python、JavaScript、Node和其他语言。一个最简单的方法开始刮是使用蟒蛇和美丽的汤。
用python抓取网站
只要安装了Python和BeautifulSoup,入门只需要几行代码。这里有一个小脚本,以获得一个网站的来源,让BeautifulSoup评估它。
from bs4 import BeautifulSoupimport requestsurl = "http://www.athleticvolume.com/programming/"content = requests.get(url)soup = BeautifulSoup(content.text)print(soup)非常简单,我们向一个URL发出GET请求,然后将响应放入一个对象中。打印对象将显示URL的HTML源代码。这个过程就像我们手动访问网站并单击“查看源代码”。
具体来说,这是一个网站,张贴交叉适合风格的锻炼每天,但只有一天。我们可以构建我们的scraper来获取每天的训练,然后将其添加到训练的汇总列表中。基本上,我们可以创建一个基于文本的训练历史数据库,以便轻松搜索。
BeaufiulSoup的神奇之处在于,它能够使用内置的findAll()函数搜索所有HTML代码。在这个特定的例子中,网站使用了几个“sqs block content”标签。因此,脚本需要遍历所有这些标记并找到我们感兴趣的标记。
此外,该节中还有许多标记。脚本可以将每个标记中的所有文本添加到局部变量中。为此,请向脚本中添加一个简单的循环:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += ''瞧!刮网器诞生了。
扩大刮削
前进有两条路。
探索web抓取的一种方法是使用已经构建的工具。网站刮刀(伟大的名字!)拥有200000用户,使用简单。此外,Parse Hub允许用户将搜集的数据导出到Excel和Google工作表中。
此外,webscraper还提供了一个Chrome插件,可以帮助可视化网站的构建过程。从名称来看,最棒的是OctoParse,它是一个强大的刮刀,具有直观的界面。
最后,既然你已经了解了网页抓取的背景知识,提高你自己的小网页抓取器,使其能够自己爬行和运行是一个有趣的尝试。
- 发表于 2021-03-22 00:36
- 阅读 ( 217 )
- 分类:编程
你可能感兴趣的文章

网上交友如何利用数据找到你的完美伴侣
... 你的网上约会成功案例是什么?你认为网上约会是未来吗?还是你更喜欢IRL约会?请在下面的评论中告诉我们! ...

使用非facebook活动工具停止被网上广告跟踪
... 什么是离开facebook的活动工具(the off-facebook activity tool)? ...

如何找出任何一家大型科技公司对你的了解
... 无论您被迫做什么,最终访问数据通常意味着下载一个压缩文件夹,其中包含一系列文件,通常扩展名不同,如.csv或.json。 ...
什么是谷歌分析,它是如何衡量的?
...他们网站的神秘虚拟访客感到好奇。有多少人?他们在读什么?加拿大人使用Firefox每个会话查看多少页? ...

最好的网上刮网工具
... 相关:什么是网页抓取?如何从网站收集数据 ...

获取机器学习项目数据集的4种独特方法
... 为什么你的数据科学项目需要更多的数据 ...
如何管理linkedin收集的数据
...过,在这个过程中,它收集了很多关于你的数据。以下是如何管理网站上的数据隐私设置。 linkedin对你了解多少 LinkedIn是一个社交网站,它允许你寻找工作,与你所在领域的人建立联系,并公开展示你的职业经历。然而,要充...
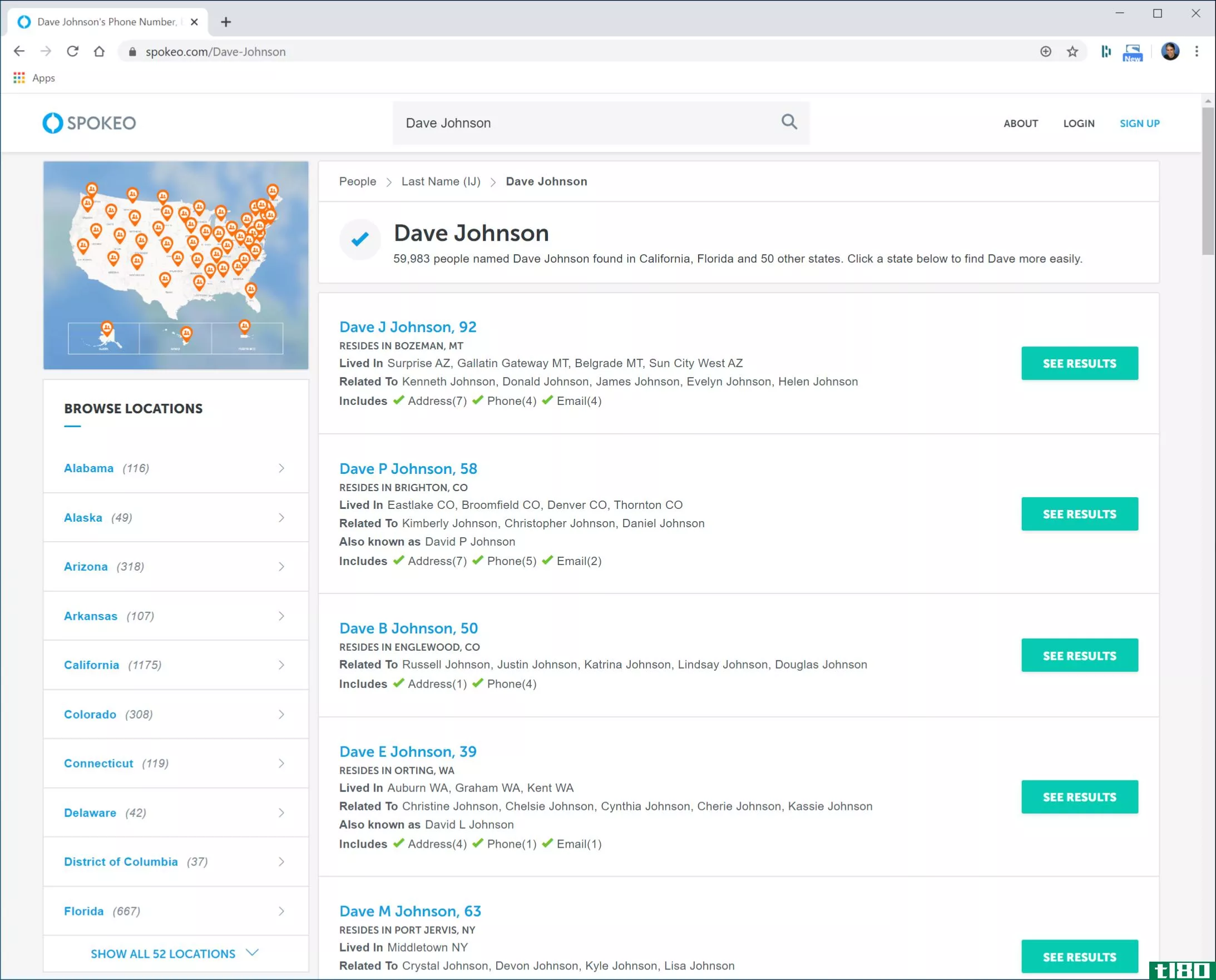
如何从人员查找网站删除您的个人信息
...。 “这在欧洲是非法的,”海宁说。“但在美国,没有什么能阻止他们为此收费。” 总体而言,删除信息并不难,它只是繁琐和耗时,这是有意的。如果你想得到一些帮助,删除我提供了一些最常见的网站的详细说明。隐私保...
别紧张,nvidia的遥测系统不是刚开始监视你的
...都是它正常工作所必需的。 那些新的遥测过程(目前)什么也做不了 当人们注意到最新的NVIDIA驱动程序添加了一个“NVIDIA遥测监视器”或NvTmMon.exe文件,进入任务计划程序。MajorGeeks甚至建议使用Microsoft Autoruns软件禁用这些任...

原始数据(primary data)和辅助数据(secondary data)的区别
...文章、内部记录等。 准确性和可靠性 更多 相对较少 什么是原始数据(primary data)? 原始数据是研究者通过直接努力和专业知识首次获得的信息,特别是为了解决他的研究问题。也称为第一手数据或原始数据。由于研究是由组...
0 篇文章





