你可能感兴趣的文章
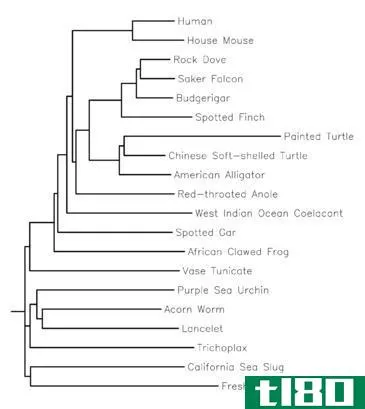
upgma公司(upgma)和邻接连接树(neighbor joining tree)的区别
... 摘要 什么是upgma公司(upgma)? 在生物信息学中,有不同的聚类技术。UPGMA代表未加权对组方法和算术平均数。它是一种分层分组方法。这种方法是由索卡尔和米切纳介绍的。这是发展系统进化树的最快技术。由此产生的系统发生...

酚类(phenetics)和分支学(cladistics)的区别
...学有助于对各种系统进行分类,同时有助于对生物体进行聚类和分组。在这一点上,酚类和支系学在建立生物体之间的关系方面起着重要作用。 目录 1. 概述和主要区别 2. 什么是酚类 3. 什么是分支学 4. 酚类与分支学的相似性 5. ...
被监督的(supervised)和无监督机器学习(unsupervised machine learning)的区别
...机器学习相关的算法有很多种。其中一些是回归、分类和聚类。开发基于机器学习的应用程序最常用的编程语言是R和Python。也可以使用其他语言,如java、C++和MATLAB。 目录 1. 概述和主要区别 2. 什么是监督学习 3. 什么是无监督学...
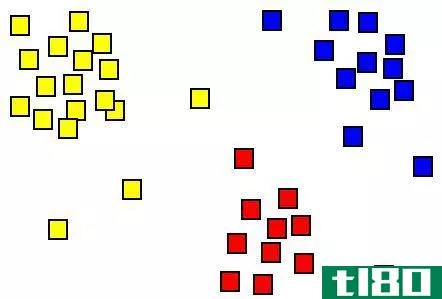
聚类(clustering)和分类(classification)的区别
聚类与分类的关键区别在于,聚类是一种基于特征对相似实例进行分组的无监督学习技术,而分类是一种基于特征为实例分配预定义标签的监督学习技术。 尽管聚类和分类看起来是相似的过程,但基于它们的含义,它们之间...
斐波那契簇
什么是斐波那契簇(fibonacci clusters)? Fibonacci聚类是一组基于不同价格波动的Fibonacci回溯或延伸水平在一个价格区域附近**。集群理论认为,如果多个斐波那契延伸或回溯水平接近一个价格,该价格可能是一个重要的支撑或阻力区...
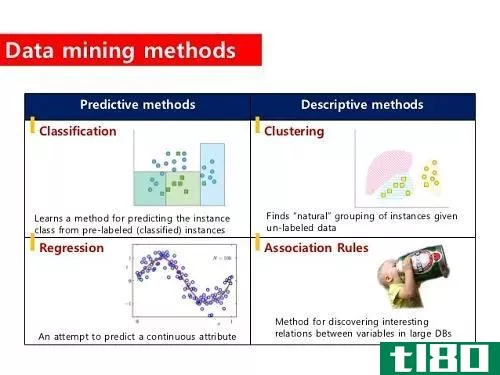
聚类(clustering)和分类(classification)的区别
聚类和分类技术被用于机器学习、信息检索、图像调查和相关任务中。 这两种策略是数据挖掘过程的两个主要部分。在数据分析领域,这些是管理算法所必需的。具体来说,这两个过程都将数据划分为多个集合。这项任务在当...

如何illumina测序工作(illumina sequencing work)
...段。Illumina测序工作流程涉及的四个基本步骤是库准备、聚类生成、测序和数据分析,本文将对此进行进一步描述。 覆盖的关键领域 1.什么是Illumina测序-定义、事实、优势2.Illumina测序如何工作-Illumina测序过程:–文库准备–...

数据挖掘(data mining)和数据仓库(data warehousing)的区别
...使数据适合于数据挖掘。第三步是数据挖掘。它使用诸如聚类、回归、分类等技术或算法来提取数据的模式。第四步是模式评估。它检查获得的输出的准确性。最后一步是用图表表示结果。 Figure 1: Data Mining 进行数据挖掘的主要...

upgma公司(upgma)和邻居连接树(neighbor joining tree)的区别
...树的主要区别在于UPGMA是一种基于平均连锁法的凝聚层次聚类方法,而邻接树是一种基于最小进化准则的迭代聚类方法。此外,UPGMA生成有根系统发育树,邻接树生成无根系统发育树。由于UPGMA方法假设进化速率相等,分支尖端的...

聚类(clustering)和分类(classification)的区别
...行任务。机器学习被广泛应用于医学、邮件过滤等领域,聚类和分类采用统计方法来收集数据,特别是在机器学习领域。聚类(clustering) vs. 分类(classification)聚类与分类的区别在于,聚类将对象或数据组织在聚类中,这些对象或数...
0 篇文章





