什么是相关聚类?(correlation clustering?)
关联聚类是在数据库和其他大型数据源上执行的,以将相似的数据集组合在一起,同时也提醒用户注意不同的数据集。这可以在某些图形中完美地完成,而其他图形则会出现错误,因为很难区分相似数据和不同数据。对于后者,相关聚类将有助于自动减少错误。这通常用于数据挖掘,或搜索笨拙的数据以寻找相似性。不同的数据通常会被删除,或放在单独的集群中。

当使用相关聚类函数时,它会根据用户的指示搜索数据。用户将告诉程序要搜索的内容,以及在找到时将数据放在何处。这通常适用于非常大的数据源,因为手动搜索数据是不可能的,或者需要花费太多的时间。可以有完全聚类,也可以有不完全聚类。
完美集群是理想的场景。这意味着只有两种类型的数据,一种是用户正在查找的数据,而另一种是不需要的数据。所有积极的或需要的数据都放在一个集群中,而其他数据则被删除或移动。在这个场景中,没有混乱,一切都很完美。
大多数复杂图不允许完美聚类,相反,它们是不完美的。例如,图形有三个变量:X、Y和Z。X、Y相似,X、Z相似,但Y、Z不同。然而,这三个变量聚类是如此相似,以至于不可能有完美的相关性聚类。该程序将最大化正相关性的数量,但这仍然需要用户进行一些手动搜索。
在数据挖掘中,尤其是在处理大型数据集时,相关聚类用于将相似数据与相似数据分组。例如,如果一家企业为一个大型网站或数据库挖掘数据,并且只想知道某个特定方面,那么搜索该方面的所有数据将花费很长时间。通过使用聚类公式,将数据留作适当分析。
不同的信息仅根据用户指令处理。用户可以选择将不同的数据发送到不同的集群,因为这些信息可能对其他项目有用。如果数据是不需要的,只是在浪费内存,那么不同的信息就会被抛出。在不完善的聚类中,可能不会抛出一些不同的信息,因为它们与用户正在查找的数据非常相似。
- 发表于 2021-12-13 11:53
- 阅读 ( 183 )
- 分类:互联网
你可能感兴趣的文章
丛生的(clustered)和非聚集索引(nonclustered index)的区别
...–以表格形式显示**索引与非**索引 6. 摘要 什么是**索引(clustered index)? 在**索引中,索引组织实际数据。它类似于电话簿。电话号码是按字母顺序排列的。在搜索特定姓名时,可以找到相应的电话号码。因此,聚类索引以有组...
聚类(clustering)和分类(classification)的区别
... 4. 并列比较-聚类与表格形式的分类 5.摘要 什么是聚类(clustering)? 聚类是一种对对象进行分组的方法,使具有相似特征的对象**在一起,而具有不同特征的对象分开。它是机器学习和数据挖掘中常用的统计数据分析技术。探索性...
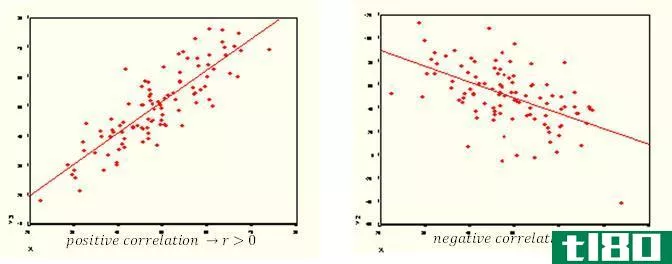
正相关(positive correlation)和负相关(negative correlation)的区别
...可用于建立变量之间的线性关系。 正相关和负相关有什么区别? •当两个随机变量之间存在正相关(r>0)时,一个变量与另一个变量成比例移动。如果一个变量增加,另一个变量增加。如果一个变量减少,另一个变量也会...
斐波那契簇
什么是斐波那契簇(fibonacci clusters)? Fibonacci聚类是一组基于不同价格波动的Fibonacci回溯或延伸水平在一个价格区域附近**。集群理论认为,如果多个斐波那契延伸或回溯水平接近一个价格,该价格可能是一个重要的支撑或阻力区...

集群(cluster)和分层抽样(stratified sampling)的区别
聚类与分层抽样 调查在市场营销、健康和社会学领域的各种研究中都有应用。他们通常是采取一个人口样本,因为对整个人口进行调查将是昂贵的。除此之外,抽样使数据收集更快,因为它只关注人口的一小部分。保证了采集...
聚类(clustering)和分类(classification)的区别
...科学解决犯罪、贫困和疾病等全球性问题。 什么是聚类(clustering)? 基本上,聚类涉及到根据相似性对数据进行分组。它主要涉及距离度量和聚类算法,这些算法计算数据之间的差异并对它们进行系统划分。 例如,学习风格相...
相关性(correlation)和回归(regression)的区别
...归还可以更准确地预测因变量对自变量给定值的取值。 什么是相关性(correlation)? In statistics, we say there is a correlation between two variables if the two variables are related. If the relati***hip between the variables is a linear one, we can express the degree to whi...

upgma公司(upgma)和邻居连接树(neighbor joining tree)的区别
...树的区别是什么?关键区别的比较 关键术语 Agglomerative Clustering Methods, Distance Matrix, Neighbor-Joining Tree, Phylogenetic Tree 什么是upgma公司(upgma)? UPGMA是Sokal和Michener提出的一种简单、凝聚的层次聚类方法。这是最简单和最快的方法建...

协方差(covariance)和相关性(correlation)的区别
...差只显示了方向,这可能不足以完全得到关系。这就是为什么我们喜欢用x和y的基本变化来分离协方差。这将有助于我们在这个过程中得到相关系数。协方差(covariance) vs. 相关性(correlation)协方差和相关性的区别在于协方差度量了...

相关性(correlation)和回归(regression)的区别
相关分析和回归分析是基于多元分布的两种分析方法。多元分布被描述为多变量的分布。相关性被描述为一种分析,它让我们知道两个变量“x”和“y”之间是否存在关联。另一方面,回归分析,根据自变量的已知值预测因变量...
0 篇文章





