什么是双聚类?(biclustering?)
双聚类是一种数据挖掘技术,它通过同时指定矩阵的行和列,将信息排序到矩阵中。这项技术的核心是效率,与单一聚类方法相比,它允许计算机在更短的时间内筛选和排序大量数据。双聚类仅仅是一类特殊的数据挖掘技术的总称;有许多不同的算法可以归入这一类,包括块聚类、格子模型、耦合双向聚类和相关双向聚类。

要理解双聚类的重要性,首先必须理解数据挖掘的一般概念。数据挖掘是将大量数据(如从公司主数据库中转储的信息)进行分类,以确定趋势和其他有用的模式。这种类型的分析可用于确定模式,否则,这些模式将不会通过偶然研究变得明显,例如消费者购买趋势和股市波动。数据挖掘可以由人工分析师手动执行,也可以使用一种数据挖掘算法进行电子操作;这就是双集群的作用。

在数据挖掘过程中,进行分析的计算机将尝试将相关的信息片段相互排序。这个过程被称为“集群”聚类允许计算机通过识别两条或多条信息何时相互关联,将它们放在一个矩阵中,从而调整其人工智能。通常,矩阵的行或列都会被填充,但一次只能填充一行或一列。
双群集通过允许计算机同时填充行和列来消除这一限制。这提高了聚类过程的效率,但会根据所使用的特定算法产生不同排列的矩阵。例如,一台计算机按行排列具有恒定匹配值的对象,而另一台计算机按列排列具有恒定匹配值的对象,将使用完全相同的值生成不同的外观矩阵。没有一种“正确”的方法来聚类数据;这完全取决于进行数据挖掘的个人的特定情况和偏好。
- 发表于 2021-12-12 19:31
- 阅读 ( 190 )
- 分类:互联网
你可能感兴趣的文章
upgma公司(upgma)和邻接连接树(neighbor joining tree)的区别
...系统进化树的两种主要方法。 目录 1. 概述和主要区别 2. 什么是UPGMA 3. 什么是邻接树 4. UPGMA与邻接树的相似性 5. 并排比较-UPGMA与表格形式的邻居连接树 6. 摘要 什么是upgma公司(upgma)? 在生物信息学中,有不同的聚类技术。UPGMA代...

酚类(phenetics)和分支学(cladistics)的区别
...间的关系方面起着重要作用。 目录 1. 概述和主要区别 2. 什么是酚类 3. 什么是分支学 4. 酚类与分支学的相似性 5. 并列比较——以表格形式列出的酚类与分支系统学 6. 摘要 什么是酚类(phenetics)? 酚类是一个研究领域,它根据生...
被监督的(supervised)和无监督机器学习(unsupervised machine learning)的区别
...他语言,如java、C++和MATLAB。 目录 1. 概述和主要区别 2. 什么是监督学习 3. 什么是无监督学习 4. 有监督和无监督机器学习的相似性 5. 并列比较-表格形式的有监督和无监督机器学习 6. 摘要 什么是监督学习(supervised learning)? 在基...
聚类(clustering)和分类(classification)的区别
...多个特征将对象特征化为组。 目录 1. 概述和主要区别 2. 什么是群集 3.什么是分类 4. 并列比较-聚类与表格形式的分类 5.摘要 什么是聚类(clustering)? 聚类是一种对对象进行分组的方法,使具有相似特征的对象**在一起,而具有不...
斐波那契簇
什么是斐波那契簇(fibonacci clusters)? Fibonacci聚类是一组基于不同价格波动的Fibonacci回溯或延伸水平在一个价格区域附近**。集群理论认为,如果多个斐波那契延伸或回溯水平接近一个价格,该价格可能是一个重要的支撑或阻力区...

集群(cluster)和分层抽样(stratified sampling)的区别
聚类与分层抽样 调查在市场营销、健康和社会学领域的各种研究中都有应用。他们通常是采取一个人口样本,因为对整个人口进行调查将是昂贵的。除此之外,抽样使数据收集更快,因为它只关注人口的一小部分。保证了采集...
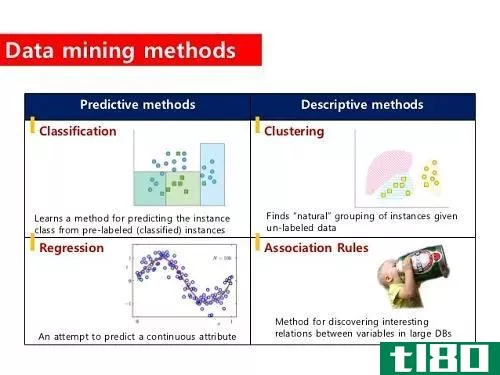
聚类(clustering)和分类(classification)的区别
...于通过数据科学解决犯罪、贫困和疾病等全球性问题。 什么是聚类(clustering)? 基本上,聚类涉及到根据相似性对数据进行分组。它主要涉及距离度量和聚类算法,这些算法计算数据之间的差异并对它们进行系统划分。 例如,...

如何illumina测序工作(illumina sequencing work)
...析,本文将对此进行进一步描述。 覆盖的关键领域 1.什么是Illumina测序-定义、事实、优势2.Illumina测序如何工作-Illumina测序过程:–文库准备–聚类生成–测序–数据分析 关键词:聚类生成、数据分析、照明测序、库准备、综...

upgma公司(upgma)和邻居连接树(neighbor joining tree)的区别
...法,与UPGMA方法相比具有更好的结果。 覆盖的关键领域 1.什么是UPGMA–定义、方法、意义2。什么是邻接树-定义,方法,意义3。UPGMA和邻居连接树之间有什么相似之处——共同特征概述4。UPGMA和邻居连接树的区别是什么?关键区...

聚类(clustering)和分类(classification)的区别
...关系。它的目标是定义对象所属的组。聚类与分类比较表什么是聚类(clustering)?聚类是机器学习的一部分,它将数据分组成具有高度相似性的聚类,但不同的聚类可能不同。它是无监督学习的方法,非常常用于统计数据分析。有...
0 篇文章





