如何计算异常值(calculate outliers)
步骤
- 1学会如何识别潜在的离群值。在决定是否从一个给定的数据集中省略离群值之前,首先,显然,我们必须识别数据集的潜在离群值。一般来说,离群值是指与数据集中其他数值所表达的趋势差别很大的数据点,换句话说,它们位于其他数值之外。通常在数据表或(特别是)图表上很容易发现这一点。如果数据集被直观地表达在图表上,离群点将 "远离 "其他数值。例如,如果一个数据集中的大多数点形成一条直线,那么离群值将不能被合理地理解为符合这条线。让我们考虑一个数据集,它代表了一个房间里12个不同物体的温度。如果其中11个物体的温度在华氏70度(摄氏21度)以内,但第12个物体,即烤箱,其温度为华氏300度(摄氏150度),粗略的检查可以告诉你,烤箱可能是一个离群值。
- 2将所有数据点从低到高排列。在计算数据集中的离群值时,第一步是找到数据集的中位数(中间值)。如果数据集中的数值按照从低到高的顺序排列,这项任务就会大大简化。因此,在继续之前,请以这种方式对你的数据集中的值进行排序。让我们继续上面的例子。下面是我们的数据集,代表一个房间里几个物体的温度。{71, 70, 73, 70, 70, 69, 70, 72, 71, 300, 71, 69}.如果我们将数据集中的数值从低到高排序,我们的新数值集是。{69, 69, 70, 70, 70, 70, 71, 71, 71, 72, 73, 300}.
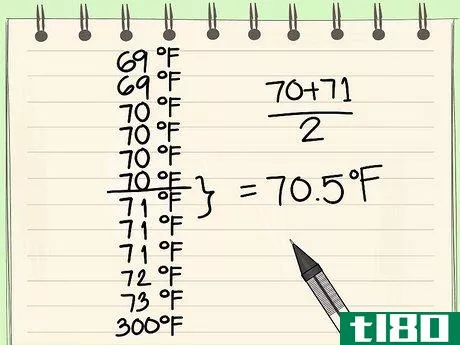
- 3计算数据集的中位数。数据集的中位数是指一半的数据位于上面,一半的数据位于下面的数据点--本质上,它是数据集中的 "中间 "点。如果数据集包含奇数的点,这很容易找到--中位数是指其上方和下方的点数量相同的点。然而,如果有偶数个点,那么,由于没有单一的中间点,应该对两个中间点进行平均以找到中位数。请注意,在计算离群值时,中位数通常被指定为变量Q2---这是因为它位于Q1和Q3之间,即下四分位数和上四分位数,我们将在后面定义。不要被点数为偶数的数据集所迷惑---两个中间点的平均值往往是一个没有出现在数据集本身的数字---这是好的。然而,如果中间的两个点是同一个数字,显然,平均数也将是这个数字,这也是可以的。在我们的例子中,我们有12个点。中间的两个项是第6和第7点,分别是70和71。因此,我们的数据集的中位数是这两个点的平均值:((70+71)/2),=70.5。
- 4计算下四分位数。这个点,我们将把变量Q1分配给它,是25%(或四分之一)的观察值所处的数据点。换句话说,这是你的数据集中低于中位数的点的中间点。如果有偶数的值低于中位数,你必须再次平均两个中间值来找到Q1,就像你可能要做的那样,找到中位数本身。这意味着,为了找到下四分位数,我们需要对底部6个点中的两个中间点进行平均。底层6个点中的第3和第4点都等于70。因此,它们的平均值是((70+70)/2),=70。70将是我们Q1的数值
- 5计算出上四分位数。这个点被指定为变量Q3,是25%的数据位于其上方的数据点。找到Q3与找到Q1几乎相同,只是在这种情况下,要考虑到中位数以上的点,而不是中位数以下的点。继续上面的例子,中位数以上6个点中的两个中间点是71和72。对这两个点进行平均,可以得到((71+72)/2),=71.5。71.5将是我们第三季度的数值。
- 6找出四分位数范围。现在我们已经定义了Q1和Q3,我们需要计算这两个变量之间的距离。从Q1到Q3的距离是通过从Q3减去Q1而得到的。你得到的四分位数范围的值对于确定数据集中非离群点的边界至关重要。在我们的例子中,我们的Q1和Q3的值分别是70和71.5。为了找到四分位数范围,我们要减去Q3-Q1:71.5-70=1.5。注意,即使Q1、Q3或两者都是负数,这也是可行的。例如,如果我们的Q1值是-70,我们的四分位数范围将是71.5-(-70)=141.5,这是正确的。
- 7找到数据集的 "内部栅栏"。通过评估异常值是否落在一组被称为 "内部围栏 "和 "外部围栏 "的数字边界内来识别。落在数据集内部围栏之外的点被归类为小离群点,而落在外部围栏之外的点则被归类为大离群点。要找到你的数据集的内部栅栏,首先,用四分位数范围乘以1.5。然后,把这个结果加到Q3,再从Q1中减去。在我们的例子中,四分位数范围是(71.5-70),或1.5。用这个数字乘以1.5,得到2.25。我们把这个数字加到Q3,再从Q1中减去,就可以找到内围栏的边界,如下所示:71.5+2.25=73.7570-2.25=67.75因此,我们内围栏的边界是67.75和73.75。在我们的数据集中,只有烤箱的温度--300度--位于这个范围之外,因此可能是一个温和的离群值。然而,我们还没有确定这个温度是否是一个主要的离群点,所以在这之前,我们不要得出任何结论。
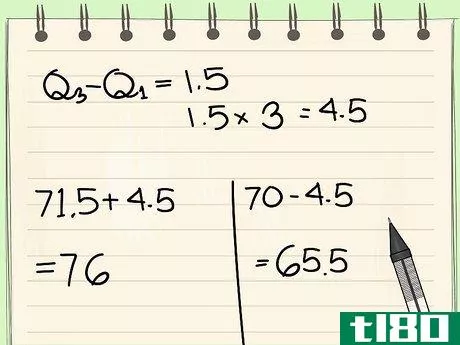
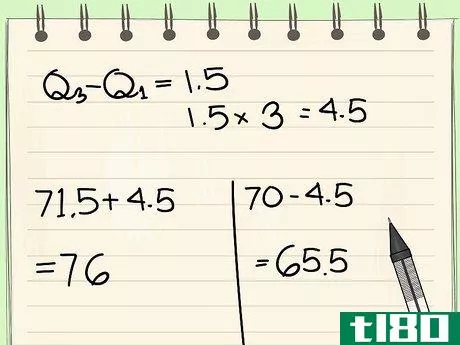
- 8找到数据集的 "外围栏"。这与内围栏的方法相同,只是四分位数范围要乘以3,而不是1.5。在我们的例子中,将上述四分位数范围乘以3,得到(1.5*3),或4.5。我们以同样的方式找到外围栏的边界:71.5+4.5=7670-4.5=65.5我们外围栏的边界是65.5和76.任何位于外围栏之外的数据点都被认为是主要的离群值。在这个例子中,烤箱的温度是300度,远远超出了外部围栏,所以它绝对是一个主要的离群值。
- 9使用定性评估来确定是否要 "抛出 "异常值。使用上述方法,可以确定某些点是小的离群点、大的离群点,还是根本就不是离群点。然而,不要搞错了--将一个点确定为离群点只是标志着它是一个可以从数据集中省略的候选点,而不是一个必须被省略的点。一个离群点与数据集中的其他点不同的原因,对于决定是否省略离群点至关重要。一般来说,可以归因于某种错误的离群点--例如测量、记录或实验设计的错误--会被省略掉。另一方面,那些不能归因于错误的离群值,如果揭示了新的信息或没有预测到的趋势,通常不会被省略。另一个要考虑的标准是离群值是否对数据集的平均值(平均数)产生了明显的影响,使其出现倾斜或误导。如果你打算从你的数据集的平均值得出结论,这一点尤其重要。让我们评估一下我们的例子。在我们的例子中,由于烤箱极不可能通过某种不可预见的自然力量达到300度的温度,我们可以近乎肯定地得出结论:烤箱被意外地打开了,导致了异常的高温读数。另外,如果我们不省略离群点,我们的数据集的平均值是(69+69+70+70+70+71+71+72+73+300)/12=89.67度,而如果我们省略离群点,平均值是(69+69+70+70+70+71+71+72+73)/11=70。55.由于离群值可以归因于人为错误,而且说这个房间的平均温度接近90度是不准确的,我们应该选择省略我们的离群值。
- 10了解(有时)保留异常值的重要性。虽然有些异常值应该从数据集中省略,因为它们是错误造成的,并且/或者以不准确或误导的方式歪曲结果,但有些异常值应该被保留。例如,如果一个异常值似乎是真正获得的(也就是说,不是错误的结果)和/或对被测量的现象提供了一些新的见解,它们就不应该被轻易地遗漏。科学实验在处理异常值时是特别敏感的情况--省略一个错误的异常值可能意味着省略了标志着一些新趋势或新发现的信息。例如,假设我们正在设计一种新的药物来增加鱼场中鱼的大小。我们将使用我们的旧数据集({71, 70, 73, 70, 70, 69, 70, 72, 71, 300, 71, 69}),只是,这次,每个点将代表一条鱼从出生起就被不同的实验药物治疗后的质量(以克为单位)。换句话说,第一种药物使一条鱼的质量为71克,第二种药物使另一条鱼的质量为70克,以此类推。在这种情况下,300克仍然是一个很大的离群值,但是我们不应该省略它,因为假设它不是由于错误造成的,它代表了我们实验中的一个重大成功。产生300克鱼的药物比其他所有药物的效果都好,所以这一点实际上是我们数据集中最重要的一点,而不是最少的一点。









- 当发现异常值时,在将其从数据集中舍弃之前,要试图解释它们的存在;它们可能指向测量错误或分布中的异常情况。
- 发表于 2022-03-11 15:07
- 阅读 ( 86 )
- 分类:教育
你可能感兴趣的文章

如何(以及为什么)在excel中使用outliers函数
离群值是一个明显高于或低于数据中大多数值的值。当使用Excel分析数据时,异常值会使结果产生偏差。例如,数据集的平均值可能真正反映了您的值。Excel提供了一些有用的函数来帮助管理异常值,让我们来看看。 一个简单的...

离群者:创造你穿过的最高科技的裤子
Outlier是一家总部位于纽约的公司,为现代都市人生产非常漂亮的裤子:它们像睡衣一样舒适,防水,防臭,而且很帅— 这一切都归功于瑞士织物炼金术士Schoeller Technologies创造的一些非常酷的技术。周五在纽约举行的PSFK会议上...

如何计算缓冲容量(calculate buffer capacity)
...(摩尔浓度moldm-3)和∆pH=添加强碱或强酸引起的pH差。 如何计算缓冲区容量 第1步:取1 dm3感兴趣的缓冲液(1升) 第2步:使用精确校准的pH计pHx测量初始pH值。 第三步:加入已知量的强酸/强碱,混合均匀,使溶液达到平衡。 步...

如何计算tlc的rf值(calculate rf values for tlc)
...合物。 覆盖的关键领域 1.什么是TLC–定义、原理、用途2.如何计算TLC的Rf值–Rf值的计算 关键词:流动相,迁移率,射频值,固定相,分离,薄层色谱(TLC) 什么是薄层色谱(tlc)? TLC是一种色谱技术,负责根据有机化合物的相...

如何计算期望值(calculate the expected value)
...应该在一场机会游戏的多次尝试中预期发生的事情。 如何计算期望值 上面提到的狂欢节游戏是一个离散随机变量的例子。变量不是连续的,每个结果都以一个数字呈现给我们,可以从其他结果中分离出来。要找到具有结果x1...

如何计算标准差(calculate standard deviation)
...标准差功能。但是,您可以手动执行计算,并且应该了解如何执行。 计算标准差的不同方法 计算标准差的方法主要有两种:总体标准差和样本标准差。如果从总体或集合的所有成员收集数据,则应用总体标准偏差。如果您...

如何计算弱酸的ph值(calculate the ph of a weak acid)
计算弱酸的pH值比测定强酸的pH值要复杂一些,因为弱酸在水中不会完全解离。幸运的是,计算pH值的公式很简单。这是你要做的。 关键收获:弱酸的ph值 测定弱酸的pH值比测定强酸的pH值要复杂一些,因为弱酸不能完全分解...

如何计算百分比误差(calculate percent error)
...告测量值或实验值与真实值或精确值之间的差异。下面是如何计算百分比误差,并给出一个计算示例。 关键点:百分比误差 百分比误差计算的目的是测量测量值与真实值的接近程度。 百分比误差(百分比误差)是实验值和...

如何计算化学实验误差(calculate experimental error in chemistry)
误差是测量实验中数值准确性的一种方法。能够计算实验误差是很重要的,但计算和表示实验误差的方法不止一种。以下是计算实验误差的最常用方法: 误差公式 一般来说,误差是指可接受或理论值与实验值之间的差值。 ...

如何计算密度-工作示例问题(calculate density - worked example problem)
...积时,计算对象和液体密度所需的步骤。 关键要点:如何计算密度 密度是指一个体积中含有多少物质。密度较大的对象比相同大小的密度较小的对象重。密度低于水的物体会浮在上面;密度越大的人就会下沉。 密度方程为...
0 篇文章